学部生での研究インターンでの学びと現在の博士課程留学 (MSR Internship アルムナイ Advent Calendar 2020)
この記事は Microsoft Research Internship アルムナイ Advent Calendar 2020 - Adventar の22日目の記事です。
はじめに
アメリカシアトルにあるワシントン大学コンピュータサイエンス博士課程に在籍している浅井明里と申します。 専門は自然言語処理 (Natural Language Processing, NLP) で主に質問応答や多言語自然言語処理といった分野を中心に研究をしています。
昨年の3月に東京大学工学部の電子情報工学科を卒業し、学部時代は他に自然言語処理の心理学分野への応用や深層学習の不確かさ推定のような研究にも取り組んでいました。 様々な巡り合わせと当時の指導教官や学部の先生方のご尽力により、学部4年次の10-1月にMSRAの自然言語処理グループでインターンをさせていただくことができました。 より詳しいプロフィールはこちらをご覧ください。 akariasai.github.io
この記事では今回の記事ではMSRAインターンの経験や現在の博士課程留学を中心に、当時のインターン経験で得た反省が現在にどう活きているかなど書いていきたいと思います。
MSRAインターン

インターンに行くことになった経緯
学部3年次から卒業後はアメリカの大学院のコンピューターサイエンス (CS) 博士課程に進学したいと考え始めました。しかし北米トップ大学のCSの博士課程は合格率5~10%前後と競争がかなり激しく、学部生であっても入学前にある程度の研究経験と出版論文が要求されるようになりつつあります。そのため学部生の間は研究できる機会があれば学内外問わず積極的に挑戦するようにしていました。
学部3年後期の情報可視化実験 (以前MSRAで研究されていた矢谷先生による演習型授業の一つ)がきっかけで、MSRAアウトリーチの鎌倉さんから研究インターンの募集をしているという話を伺い、ダメもとで応募してみました。当時は出版論文や研究経験的にもかなり心許なかったのですが、大変幸運なことに希望していた質問応答グループの方からオファーをいただくことができました。竹岡さんのアドベントカレンダー記事でもあったように応募して損はないので興味があったらとりあえず応募してみるのが大切だと思いました。
卒業論文を早めに進め、夏までにメインの実験や執筆を完了させてインターン期間中はできるだけインターンの研究に集中するようにしていました。ちょうど同じ時期に大学院の出願作業*1を行う必要があり、当時はあまり他のインターンの方と交流したりできなかったのが心残りですが、とても充実した3.5ヶ月を過ごすことができました。
研究について
インターン中はMSRAのQuestion Answering (QA) - Microsoft Researchチームに所属し、様々なKnowledge Sources (知識グラフや大規模なウェブコーパスなど) の情報を活用してより性能の良く説明性の高いCommon Sense Reasoningモデルを作る研究を行っていました。2018年の冬はちょうど大規模事前学習モデル (BERT) の登場によりNLP分野が大きな転換点を迎えたタイミングであり、自分自身とてもわくわくしていたものの、インターンのプロジェクトとしては難しい舵取りが必要になり多くの学びがありました。
大規模事前学習モデル (BERT) の登場とその衝撃
MSRAに滞在し始めた直後の2018年10月、GoogleからNLP分野の大きな転換点となる大規模事前学習モデル (BERT) の論文が発表されました。 arxiv.org これは大きな深層学習モデルを大量のウェブ文書を使い、予め欠損させた単語を予測させるなどのシンプルなタスクで学習させ、その後質問応答や分類など様々なNLPタスクに転用するもので、従来モデルを大幅に上回る性能を多数のタスクで示しました。さらにいくつかのタスクではHuman Performanceさえも上回る性能を叩き出しました。まだ発表されてから2年ほどしか経っていないにも関わらず、すでに1万引用を超えており、現在様々なNLPタスクにおいて、BERTもしくはそれの派生モデルが最高性能を誇っています。また実世界においても、BERTは現在Google検索などに幅広く活用されているようです。
学部4年生前半は深層学習の予測不確かさ推定という研究をいくつかのコンピュータビジョン (Computer Vision, CV) タスクで行っていたのですが、CV分野では一般的な事前学習モデルの活用をNLPで行うならどういったアプローチがあるのだろうかと当時考えていました。BERTにより大規模な事前学習及その広範なタスクへの転移が極めて強力であると示されたこと、またすぐにモデルがリリースされ、PyTorch*2でのオープンソースライブラリの開発が急ピッチで進む様はとても刺激的でした。 MSRAのQAグループでも毎週のようにBERTをどう今の研究に取り入れていくかなどを活発に議論したり、Bing検索の改善に活用できないか様々な実験などを行っていたのもとても印象に残っています。
インターンへの影響
BERTの登場をとても興味深く思う一方で、インターンの研究プロジェクト的にはかなり困った状況になっていました。実はMSRAに着いてから最初の一ヶ月ほどは別の研究を行っていたのですが、当時私はBERTが「人間の性能を超えてしまった」データセットの一つに取り組んでおり、従来型のモデルを改善した提案手法はBERTの性能に遠く及びませんでした。もちろんBERTをさらに改善すると言う方向性もあったとは思うのですが、「既にHuman performanceを上回る性能が出ているのにこれ以上の改善したとしてもそれは評価されるのか、そもそもデータセットの方になんらかの問題があったのではないか」とメンターと話し合い、プロジェクトの方向性自体を考え直すことにしました。その結果、インターン開始から一ヶ月以上経ってから前述のプロジェクトに新しく着手することになりました。
インターンプロジェクトでの反省
残り時間が限られていたことから、当時はあまりじっくりと新しいテーマの方向性についてメンターと議論をしたり事前実験をすることなく、大まかに全体像を決めたあとすぐに細かい実装や実験を開始してしまいました。個人的にはその当時の進め方には反省している部分も多いのですが、自分のその後の研究の進め方やスタイルを大きく修正するきっかけになりました。
反省 (1) 予めその研究のContributionsが十分に考えられていなかった
「限られた時間の中でなんとか区切りのいいところまで終わらせられそうな研究を」という視点から新しいテーマを考えてしまったために、既存手法に要素を追加していくインクリメンタルな方向性になってしまい、具体的にどこに新規性があり、何がコントリビューションとなるのかが明確ではないまま研究を開始してしまったと思います。そのためにプロジェクトの終盤付近で「一応結果は出ているがこれだけではContributionsが小さくトップ会議は難しいので、この手法もなんとか取り入れられないか」とメンターから提案をされ議論になったりもしました。ベースラインを実装し、そこにいくつかの有効な手法を積み上げ state of the art (SOTA)を目指すというのも一つの研究の仕方ではある (そして特に最近そういった論文は増えている) とは思いつつ、自分の中で関連性の薄い既存手法を繋ぐことに納得ができていなかった部分があったと思います。
現在の指導教官からは新しい研究プロジェクトに取り組む際によく「私がこの研究のコントリビューションを簡潔に3つ挙げてと言ったら今すぐに答えられる?」と聞かれます。これはコントリビューションが不十分な研究の場合、なんとか論文化まで仕上げたとしても、トップの会議やジャーナルには採択されずPublicationにつながらない(そしてインパクトが限られた研究になる)ためらしいです。また即座に自分の言葉でContributionsが語れないならばまだ自身で考えが整理できていないということでもあるので、プロジェクト途中で立ち止まるリスクも大きいからのようです。
厳密に何個コントリビューションがあるから必ずしも良い研究になるというわけではないのですが、まず新たなプロジェクトを始める前にどの問題に取り組みたいのか、どういった手法が有効になりうるのか、またその研究が結果的に分野にどのようなコントリビューションをもたらすのかを事前に徹底的に考える必要性を強く感じました。
反省 (2) 十分な事前実験や分析を行わずに研究に着手した
また、提案する手法が実際に有効となりうるのか検証するために、必要な予備実験を行ったり、ベースライン手法で何ができていないかなどを徹底的に分析するなどが不十分であったこともよくなかったと思います。(1) と関連するのですが、まず現状の課題 (e.g., SOTAモデルに何ができて何ができていないのか) をきちんと理解し、提案手法がその課題に有効に作用しうるかをコンロール実験で検証したり、データを徹底的に分析してタスクやデータセットの特色を把握してから実際の提案手法の実装なりを開始すべきであったと思います。当時はこの検証が十分でなかったために、ある程度時間をかけて実装した手法がベースラインと比較して性能的に大きな差はないというような結果になったりし、結果的に遠回りすることになってしまったりもしました。
現在ではまず研究を始める前に 「①ベースライン手法のエラー分析を徹底的に行う→②どういった問題が解けていないのかを定性的定量的に調べる→③見えてきた特に興味深い問題に効果的に作用しそうな大枠の手法の方向性を考える→④ナイーブではあるが大枠の方向性と似た特徴のあるベースラインモデルを実装し、実験する」のサイクルをひたすら回すようにし、④で有効性が見えて始めてメインの手法の実装を本格的に始めるようになりました。
反省を踏まえて
最近では研究は始める前にブレインストーミングや事前実験に1~2ヶ月近く費やすことが多くなったのですが、おかげでプロジェクト中盤や終盤での大幅な軌道修正を行ったり、査読でContributionsが不明確だとコメントを付けられることがかなり減ったような気がします。 近年NLP分野ではPublicationのサイクルが早いため、思いついたアイディアをすぐに実践し誰よりも早く世に出さなくてはいけないとプレッシャーを当時は感じすぎていたような気がします。提案手法は手段であり目的ではないことを忘れず、まず解決したいコアの問題を明確に把握し、どんな提案を行うのかを事前に考えるようにしたいと考えるようになりました。
日々の研究の進め方に関して
MSRでは週のグループミーティングに加え、担当のメンターと毎日のようにチャットをする機会があり研究のペースを保つ良いマイルストーンになっていました。次までにどんな進捗を出しておきたいか、ミーティング直後にフィードバックを踏まえて短期的な目標を立てるようになりました。またそれを達成するため、日々その日行ったことを全て記録に残しつつ、次の日に行いたい作業を洗い出しておくようになりました。
当初は日々の実験や作業のログを紙に残したたりしていたために、検索したりメンターとのチャットでそれらを出すのに時間がかかったりしていました。他の博士学生インターンの日々のルーティンを参考にして、一括してGoogle Docs (実験ノートと作業ログ) とGoogle Sheets (実験の結果とモデルやデータのファイル名、コマンドなど)、そしてGoogle Slides (進捗報告スライド) で管理して相互に参照できるようにするなど行うようになりました。これは今でも続けていて振り返りにとても役立っています。
他のインターン生との交流について
そんな感じでメインの研究が炎上気味少し大変だったたり大学院出願作業を業務時間後行ったりしていて他のインターンの方とあまり交流できなかったのは大きな心残りでした。それでも日本からのインターンの方々がよく昼ご飯や夜ご飯に誘ってくださったり、QAグループの他のインターン生とも少し交流できました。北京は外食のコスパの良さは東京以上で、「北京ダックと巨大な煮魚とその他名前はわからないけど美味しい中華料理大皿を大量に食べたのに一人1500円」といったことが多く、料理が全体的にやや脂質多めなことを除けば大満足でした。



ちょうどインターン時期はCVPR (コンピュータビジョンの最難関国際会議) やNAACL (NLPの難関国際会議) の論文締切もあり、締切前には周辺の座席の学生が連日深夜 (もしくは早朝) まで残って研究しており、彼らの熱気には驚かされました。特にCVPR前は半分以上の席でインターン生たちがギリギリまで作業しており、相当数の論文がMSRAインターンたちが主体になってに投稿されていたようです (MSRAからは毎年膨大な数のCVPR論文が採択されています)。 MSRAには博士学生インターンの他に学部卒業後アメリカなどの大学院に進学したい学部生インターンも多く在籍しており、少しでも多くの論文をトップ会議に通したいといつも熱心に研究していました。自分と歳の変わらない野心的で優秀なインターン達を見て自分も頑張らなくてはと強く思わされました。
隣の席のインターンの方には中国語がわからないときによく助けていただいたのですが (中国版ウーバーのDidiの使い方がわからず半泣きになっていたら代わりに配車の手配をしてもらったり…)、次の年のCVPRのMicrosoftのパーティーで偶然再会し、近況報告ができたりしました。その際、実は当時私が「日本人インターン生がオフィスに四六時中いてワーカーホリックでヤバい」と噂になっていたらしいことを教えてくれました。実際はMSRAのネットワーク環境が快適すぎてずっといただけなのですが*3…
アメリカでの博士課程留学
MSRA中には同時並行してアメリカの博士課程への出願を行っており (出願についての詳細な話はこちらを参考にしてください)、オファーをいただいた中から最終的にワシントン大学に進学しました。留学して以降のことは奨学金の報告書に書くのみだったので、今回のブログに少し振り返りをまとめてみました。
また最近米国大学院学生会主催のコンピューターサイエンス分野の留学説明会で少しお話させていただきました。私以外にMIT博士課程の五十嵐祐花さん、ベルリンのHasso Plattner Instituteの茂山丈太郎さん、Oxfordを卒業し現在国立情報学研究所助教の五十嵐歩美さんと大学院出願や博士課程での経験、新型コロナウィルス感染拡大下での研究など様々なトピックについて話しています。 www.youtube.com
研究について
ワシントン大学では主に自然言語処理分野の中でも質問応答や推論といった分野に取り組んでいます。博士課程進学前のMSRAや別の研究所でのインターンを通して卒論で自分の中である程度研究のやり方や興味分野が定まったこと、また指導教官や同グループの学生からかなり手厚くサポートしてもらえるおかげで順調に研究できているように思います。
最初の一年目は直前の夏のインターンで行った研究を仕上げてICLRに投稿したのと並行して新しい推論系の研究を始め、一学期目の終わりにACLに投稿して採択されました。その次のプロジェクトを見つけるために少し苦戦したのですが (細かい事前実験と指導教官との相談の結果、10近いアイディアが没になりました…) ちょうど冬学期が終わるくらい*4比較的興味のあるプロジェクトを見つけることができ、長期戦にはなりましたが先日公開することができました。
また別のNLPグループの教授から「慣れないうちは一つのプロジェクトに集中し、やり切るのが大切。ある程度経験を積んできたら、複数の研究をうまくマネージするスキルを身に付けることも大切。アカデミアでもインダストリーでも、研究者は年次が上がるほど複数の研究プロジェクトや雑務をやりくりする (juggling) スキルが必要になってくる」と言われなるほどと思い、一年目の2学期目以降からは積極的に他のグループとのコラボレーションや副プロジェクトにも参加するようになりました。結果的に二つの論文がNLPの最難関会議の一つであるEMNLPに採択され、またもう一つ共同で行っていたプロジェクトも9月に機械学習系の国際会議に投稿することができました。
現在の指導教官は質問応答や推論などの分野をリードしているAssistnt Professorで、毎週1時間程度の個別ミーティング (+Slackやメールなどでのやりとりやグループミーティング) などでかなり密にコミュニケーションがとっています。また彼女とは研究興味や分野の中でこういうことはまだできていないなどの課題意識が近く、研究の方向性やアイディアなど大きな方向性を一緒に考えたりより実践的な細かい実装や手法の改善を一緒に議論することができいつも大きな刺激を受けています。 博士課程入学前は他の博士学生と比較して論文数や研究経験が少ないことに大きなコンプレックスがあり、必要以上にPublicationへの意識が先行していました。それに対して「論文の数だけ多くとも意味がない、代表作だと思ってもらえるようなクオリティが高くかつ分野への影響力が大きい数本の論文を丁寧に仕上げていくことが大事」と研究の質に拘ること、前述の研究のコントリビューションを強く意識することをよく諭され、今は一つ一つの研究を丁寧に、かつ研究のインパクトを強く意識するようになりました。
同じ研究室の学生も似たようなトピックに取り組んでいる人がいるため、初期のアイディアについてディスカッションをしたり締切前に内部でPaper Clinic (グループ内で投稿予定の論文に1~3名程度ずつ学生を割り振り、相互に査読で指摘されそうな問題点などを事前にコメントし合う) を行うこと投稿時点での論文のクオリティをグループ内で底上げできているような気がします。コンスタントに論文を難関会議に採択させている学生は投稿に対してかなり余裕を持って研究しクオリティに拘っている人が目立ち (例えば投稿前一ヶ月までにだいたいの実験を完了し、残り一ヶ月はひたすら執筆の改善や追加的な実験を行っているなど) 、原稿がいつもギリギリ間に合っていなかった学部時代の自分を大いに反省しました。 UW NLPグループはNLP分野において世界的有数の研究グループの一つで、毎年複数本の主著論文を出版したり著名な学会でOutstanding PaperやBest Paper Awardを獲得する博士学生も毎年います。適度なピアプレッシャーはあるものの、学生同士がお互いにリスペクトし合いとても居心地の良い環境だなと思います。
特に一年目の後半になってからは、シアトルという地の利と強固な周辺の研究機関との繋がり故のメリットも強く感じるようになりました。シアトル市内及び周辺エリアはMicrosoftやAmazonの本社だけでなく、FacebookやGoogleなども拠点を拡大しつつあり、テックハブとなりつつあります。そのため各社のNLP研究グループもいくつかシアトルに存在し、UWNLPグループとはかなり活発に交流や共同研究が行われています。またAllen institute for AI*5やFacebook AI Research SeattleのNLP研究グループはUWNLPグループの教授がマネージャーを兼任しているため、彼彼女らの博士学生たちがよくPart timeで働いていたりします。こういった体制は大型のプロジェクトを行う際のリソース的なメリットを産むと同時に、現役のトップ研究者たちから学生が学んだりネットワーキングをするとても良い機会となっていると思います。
授業について
アメリカの博士課程は日本や欧米のものと比べ授業の負担が重く最初はあまり研究に時間を取れないと言われることも多いですが、所属している学部では一学期に一授業を取れば十分程度のようです。課題の提出締切前などは週20時間近くを費やす必要はあるのですが、特に専門に近い授業ですと忘れかけていた知識を補填する良い機会になりました。Breadth Requirementsというものがあり、専門外の授業もある程度履修する必要もあるため、最近はシステム系の授業で分散処理の論文を読んだり、来学期は理論系の授業を取ったりする予定です。直接的に研究に役に立つのかはやや不明ですが知識の幅を広げる良い機会になりそうです。
新型コロナウィルス感染拡大による変化
特にアメリカは新型コロナウィルスの感染拡大の影響が深刻で、今年の3月ごろからずっとフルリモート状況が続いています。今年の春ごろと最近になってまたロックダウンや外出制限が厳しくなっており、研究や生活面も大きな変化がありました。
研究面での変化
所属学部では春の時点でほとんどのミーティングや授業がフルリモートになりました。それまでは一日中オフィスに籠もって研究するようなスタイルだったのですが、Work from homeがほぼ強制になったことで住宅での仕事環境を整えるようになりました。比較的どこからでもsshでサーバーにアクセスできる環境があれば研究を進められるのはNLP分野の良い側面だなとは思います。
一方で、まとまった予算の申請やクラウドソースのための学内での手続きなどが通常より時間がかかり、当時立ち上げたばかりだった大きなプロジェクトが最初の1~2ヶ月は思うように進まず焦りを感じることはありました。また平常時はオフィスメイト (NLPの博士学生6人で一つの部屋をシェアしており年次も近いのでよくご飯に行ったり外出したりもしていました) と雑談する中でアイディアが閃いたり、実装でつまったり変なエラーに遭遇した時にすぐ相談できたりしたのですが、そう言ったコミュニケーションが減ってしまったのは残念に思います。
生活面での変化
通学の必要がなくなり、また友人と外出することもできなくなったことで、研究する時間自体は増えたように思います。一方で、休日も平日もほぼ外出せず朝起きてから寝るまで作業するような生活を一ヶ月程度続けたあたりで生産性が落ちているのを感じるようになりました。そのため4月くらいからはある程度時間を決めて休む時間は休むようになりました。
ただ一時期は本当に食料品の買い出し以外一切の外出ができなかったので、ひたすら電子漫画を読んだり小説を読んだり(サイトの本棚を見ると今年は700冊くらい読んでいたようです)、NetflixでSherlockやHouse of Cardsを見たりしていました。時間に余裕が出たことで毎日自炊をしたり筋トレランニングができるようになったので、以前よりもしかしたら健康的になった部分はあるかもしれません。外出禁止令や集会への規制がやや緩和された6月以降はハイキングなどに行くことができるようになりあました。大都市でありながらも周囲にハイキングスポットなどが充実しているのはシアトル市のとても良い点だと思います。

学会の変化 (バーチャル国際会議)
今年はいくつかの国際会議で研究発表を行ったり聴講をしたりしました。事前に発表動画を録画し、質疑応答のみZoomセッションで行う形式であったため、論文の内容を理解した上で質問に来る参加者も多く質疑応答はかなり密なやりとりができていたような気がします。一方で他の参加者と交流する機会はあまりなく、また「バーチャルだと国際会議期間中であっても通常のミーティングだったり業務が入れられるため、学会に集中できない」という声もよく聞きます。今年はACL、EMNLPそしてICLRという3つの会議に参加しましたが自分の発表以外のセッションはあまりアクティブに参加できていなかった気がします。来年以降、国際会議がどう言ったフォーマットになっていくのか注視していきたいと思います。
振り返ってみて
MSRAで過ごした3ヶ月間は色々苦戦することも多かったですが、改めて自分の研究興味やスタイル、そして足りていない部分を見つめ直すとても良い機会になりました。また昼夜研究に勤しむ他のインターン生らを見て自分ももっと頑張らなくてはと大きな刺激を受けました。また当時はまだ研究実績が少なく、学部生であったので応募自体少し悩んだのですが、一歩踏み出せて本当に良かったと思います。
日本の学部からアメリカのコンピューターサイエンス博士課程に出願する
このブログでは日本(の学部)からアメリカのコンピューターサイエンス博士課程へ出願した際のスケジュールや行った対策についてまとめています。
- はじめに
- 必要な書類やその対策
- 合格可能性を上げるためにした方が良いこと
- これまで質問されたこと
- 参考になるブログなど
- 質問など
はじめに
自己紹介
今年3月に東京大学の工学部電子情報工学科を卒業し、9月から第1志望であったシアトルにあるワシントン大学のコンピュータサイエンス博士課程に進学予定です。もともと文科2類 (経済学部への進学が一般的)で入学し、経済学部に一旦進学したのちに学部での留学を経て工学部に転学部しました。
昨年12月にアメリカの大学院11校に出願し、進学予定の大学の他にカーネギーメロン大学・コーネル大学・ジョンズホプキンス大学等6校から博士課程での合格をいただきました。 学部の間は自然言語処理を中心にコンピュータービジョン、機械学習などを研究し、博士課程でもこれらの研究を継続する予定です。
アメリカのCS博士課程とその合否決定プロセス
学部卒業後、2年の修士課程(博士前期課程)に進学し、その後3年程度の博士課程(博士後期課程)に進学する日本と異なり、アメリカの大学院では将来的に研究キャリアを目指す(特にアメリカの大学の)学生は学部卒業後、そのまま一貫した5年程度の博士課程に直接進学するケースも一般的です*1。また、アメリカの博士課程では授業料及び生活費は大学(学部や指導教官のグラントなど)からRA/TAなどの形で賄われるため、学生本人が負担しなくて良いことが多いです。1.5~2.5年目あたりで実施される予備審査を突破するまでの期間は授業の履修がある程度必要ですが、毎学期複数の苛烈な授業を取る必要があるアメリカの修士課程と比較すると負担はそこまで大きくないと思います (日米データサイエンティスト教育の違い)。
アメリカの(少なくともCSの)博士課程は、複数の出願資料(と面接)に基づき複数名の教授などで構成されるアドミッションコミッティーにより、以下のようなプロセスで合否が決定されます。
- 成績、英語テストのスコア(TOEFL及びGRE)による足切り
- 在籍する博士学生と比較的若い教授が足切りを突破した学生に対し、学部の大学*2/履歴書/研究実績/SoP/推薦状等に基づいてランクをつけ*3、ランクの高い学生を選抜候補者名簿(shortlist)に載せる(ここまでが第一段階でのフィルタリングとされ、数百程度まで候補者を絞り込みます)。
- (このプロセスは大学によっては存在しないことも)shortlistは更に別の教授手渡されて更にshortlistの中から候補者を絞り込む。
- 残った候補者のリストがそれぞれの教授に送られる。またもし応募フォームもしくはSoPに一緒に働きたい教授に言及する場合、その教授陣にその旨とともに送られる*4。
- (このプロセスは大学によっては存在しないことも)一部の出願者*5に対して電話面接もしくは現地面接を行う。
- 出願者の詳細を確認した教授がその学生を獲得したいと思った場合、アドミッションコミッティーに推薦*6。
- アドミッションコミッティーにより合否決定。
スケジュール
以下が私のアメリカ大学院出願時の実際のスケジュールになります。

TOEFLおよびGREについては足切り程度に使われることが多いということで、最低限のスコアが取れた段階で対策を終了しました。
この件については後述するのですが、やはり中国、インドなどからの出願者はかなり高得点を獲得していることも多く、私は出願直前にそこまでスコアが高くないことで少し不安を感じていたので、
可能であれは出願する1年半程度前から勉強して、出願一年前には高いスコア(TOEFL 110, GRE Q+V: 325, AW: 4.0)が取れていると安心ではないかと思います。
これらのテストスコアは基本的には大学の窓口にETSのサイトから送る必要があり、一応出願締め切りの1ヶ月前にはこの手続きをサイトで完了しておくと締め切り直前に間に合うんだろうかとヒヤヒヤしなくて済みます。
SOPなどの出願書類は秋頃に作成を開始しました。12月に入る前には全ての必要書類が揃っていると望ましいと思います。
またカリフォルニア大学(UCバークレーなど)は研究計画や過去の研究が中心のSOP以外に自分史(Personal Statement)が必須だったり、CMU CSのLTIプログラムではビデオエッセイの提出が強く推奨されています*7。大学ごとにこういった追加的な出願資料が必要な場合があるので、11月には必要書類を一度確認して早めに作成を開始した方がいいと思います。
私は本格的に研究を始めたのが学部3年生の12月と遅く、また学部4年生の秋学期は北京で研究インターンを行っていたために、複数の研究と並行して出願を進める必要があったため、 出願書類の作成等はかなりバタバタしていました。 まだ出願までに1年以上猶予のある方は早い段階で研究実績を残して出願年は研究をある程度セーブした方が戦略的には良いかもしれません…
必要な書類やその対策
出願時に主に必要になるのは (1) TOEFL及びGREのスコア提出 (2) 3通の推薦状 (3) Statement of Purpose (4) 成績証明書 (5) 英文履歴書で、大学によっては上述のように追加的な資料の提出を推奨もしくは必須としています。以下これらの出願書類に関する項目を追って行きます。
どのファクターが特に重要なのか、というのは公言されてはいませんが、学部から直接PhDプログラムに出願する場合は「推薦状 >= 研究実績(≈ 英文履歴書・Publication Record) > SoP >= GPA > TOEFL及びGRE」くらいなのではないでしょうか。やはり出願時までにアドバイザと十分なコミュニケーションを取りながら、なんらかの形で国際会議やワークショップ・ジャーナルなどで発表できると、より効果的な推薦状を書いてもらえ、また研究実績という点でも目立つことができると思います。また学部からの出願の場合はGPAについてより注目されます。
TOEFL及びGRE
対策
実際の試験対策については詳しい記事が多数あるので割愛させていただきます。私はどちらもT公式ガイドブックを一通り解き、TOEFLは所属大学で受講ができた、アゴスによるTOEFL対策講座を受講しました。またGREについては一応MagooshやManhattanのFlash Card (単語帳)を使って学習しました。ただGREに関しては足切りはされない最低限のスコア(V+Qで310後半、AW で3.5)*8を取ることだけを目指し、あまり時間をかけていません…。
TOEFLのミニマムスコア
TOEFLのミニマムスコアについては各大学によってある程度ばらつきがあるのですが、情報系だと「100以上」もしくは「各セクション22(20)以上」等の基準が設けられていることが比較的多いと思います。
これらのミニマムスコアについてはおそらくかなり厳格に適用される(推薦者の一人が出願先の大学の教授もしくは元教授等、余程強いバックアップがないと書類審査の段階で不合格とされる可能性が高い)らしいので、 TOEFLについては有効期限2年が切れない範囲で早めにこの基準を超えておくとよいと思います。
TOEFLのSpeakingのみ高いスコアを要求されている
大学によっては「Speakingで26(27)」等、Speakingのみかなり高いスコアを設定していることがあります。
例えばワシントン大学(UW)CSE PhDコースでは以下のような規定があります。
The minimum TOEFL-iBT score is 80, including at least 26 on the Speaking section of the test. An applicant who does not meet the minimum required score of 80 on the TOEFL-iBT will not be considered admissible by the Graduate School.
これは主に外国人をTAとして雇用するためにこの基準を超えていることが要求されているためであり、国内奨学金から十分な支援がある、受け入れ先の教員のファンディングが潤沢であるためTA業務は卒業するために最低限で良い等の場合には超えていなくても合格をもらえることがあります。
ただ、TAは博士の修了要件として課されていることがほとんどなので、こういった制限のある大学に進学する場合、進学後に英語の授業やTOEFLの再受験や面接審査等*9が必要になってきます。
GREのミニマムスコア
GREについてはTOEFLほど厳密にミニマムが設定されているわけではないものの*10、内部での審査段階である程度目安となる点はあるようで、ある大学でアドミッションにかかわっている博士学生からは
Reasonbaleなスコア(Verbalが150、Quantativeが160以上)であれば特に気にならないが、さすがにそれ以下(特にQが160を切る)だと事実上の足切りに遭う可能性がある。ライティングについても3.5もしくはそれ以下だと気になる。できれば4.0以上が望ましい。
と聞いたことがあり、最低限この水準はクリアしたほうが安全かもしれません。
また自然言語処理で著名なJHUの先生はあまりにも低い(おそらく上述の基準以下)のスコアはネガティブなファクターとなることを示唆しています。
Answers for Prospective Graduate Students
Surprisingly low GRE scores on an otherwise strong application may just be a fluke, so they do not disqualify you, but they will make us check your application for other signs of weakness.
ただ、GREについてはTOEFLほど厳密にミニマムスコアが定義されているわけではないので、他の出願書類(例えば研究実績)が優れているの場合には多少スコアが悪くてもカバーできる可能性があります。
望ましいスコアについて
TOEFLやGREについては正式にもしくは非公式に内部で設定されている可能性があるミニマムスコアについては以上の通りなのですが、以前ある大学の先生とお話しした際に
100はミニマムであって、103や104は少し低いなと感じる。110以上あると安心する。
という話を伺ったことがあり、余裕がある場合はより高い点数を取っていたほうが不安要素を減らせそう*11です。
ミニマムを超えているがSpeakingのスコアが低い(~22)の場合はアドミッション時に悪影響を与える可能性があるので*12、推薦状で「英語でのコミュニケーション能力が十分である」というように言及してもらうといいかもしれません*13。
GREについては、各大学で「出願者の平均スコア」「合格者の平均スコア」等を公開していることがあり、これを下回っている場合、他にカバーできる材料がなければ足切りもしくはやはり出願書類が審査される際にネガティブな印象を与えてしまう可能性があります。
- University of Pennsylvania CIS Admission statistics : Fall 2018 Candidates admitted to the CIS/MSE program: Average GRE: V 159/Q 168/AW 4
- Ph.D. Admissions: Prerequisites: The average GRE scores of recent applicants were: Verbal 83% (including international applicants), Quantitative 93%, and Analytical 61% (大体 UPennと同程度のスコアでこのパーセンタイルになります)
スタンフォードやカーネギーメロンなどのトップ校でも「GREでQ+Vが320を超えていないから書類審査で落とされて教授の目に入らない」ことはないのですが、研究実績や推薦状がかなり強力(出願先の先生と個人的なコネクションがあり、かつ自分を高く評価している)であると自信が持てる場合を除き、できるだけこの望ましいスコアに到達していたほうがよいと思います。また日本からの出願者は中国等からの出願者と比べてGREで高得点を獲得しているケースが少ないらしく*14、ここで高得点を取れると一つのアピールになるかもしれません。
私は出願直前にTOEFLとGREのスコアがあまり高くないことに気を揉んでいたので、余裕がある方は早めに対策をし、よい得点を取得しておくとよいと思います。また研究実績の少ない学部生等の場合、もしくは出身校があまり知名度が高くない場合、GREのスコアを見て判断することがあると明言している先生もおりやはり320後半程度のスコアがあった方が安心はできるかもしれません。
We don't like to rely too much on the GRE, because it is just an artificial one-day exam. Very high GRE scores are most useful if your recommendations and grades come from a lower-ranked institution: your high GRE will reassure us that you will shine as brightly here as you did there.
For undergraduate applicants without research experience, GPA and grades from standardized tests are often important.
ただ出願の時期が迫っている場合は、GREについてはいくらでも研究実績でカバーできると思うので、研究経験を積む、より良い推薦状を書いてもらえるよう努力する、コンタクトをとる、などにフォーカスしたほうが良いと思います。
GPA
望ましいGPA
特に学部から直接出願する場合、3.5~4.0/4.0の間のGPAを維持したほうが良さそうです*15。 また修士からの出願者の場合でも、「学部時代のGPA」はある程度考慮されるようなので、学部時代から安定したGPAを取るのがベストかもしれません。GPAについては学部全体での数値が高くなくても専門科目(例えば東大なら後期課程)でのGPAを重視する大学*16もあり、今学部2、3年生の方は頑張って良い成績を取るといいと思います…
GPAが3.0~3.3で事実上のGPAによる足切りを行なっている大学もあり、このミニマムを下回っている場合は注意が必要かもしれません*17。 4.0/4.0は出願時に有利のようですが、これについても諸説あり、研究実績がないのにGPAだけ良いと逆に「勉強ばかりしていたのではないか」とネガティブな印象を与えてしまうこともあるらしいです*18。
ある大学の先生は
ある程度名の知れた大学であれば3.5以上あれば特に問題はないし、それ以上は大差はない(3.7も3.9もほぼ関係ない)。大学名で傾斜をつけるため、名門校出身者のGPA3.3程度の方が自分の知らない大学のGPA3.8程度より評価することもある。
とおっしゃっていました。 GPAに関してはCMUの方が書いた資料のSection3.1でもう少し詳しく言及されています。
GPAに関する懸念事項
GPAが4.0換算でない場合もしくはGPAなどを大学が成績証明書に掲載していない場合
出願にあたっては「成績証明書に記載されているGPAを入力するように。再計算した結果を勝手に記入しないこと」などと求められるケースが多いと思いますが、大学によってはGPAがそもそも4.0換算でないもしくは成績表に掲載されていないケースもあるかと思います。東大ではオンラインのサイトではGPAが確認できるにも関わらず公式の成績証明書には掲載されていません。また、D(不可)が成績評価に存在するにも関わらず、成績証明書に「成績証明書は優上、優、良、可の4段階」と表記されているため、「もし優上を4.0、優を3.0、良を2.0、可を1.0で向こうで再計算されたらどうしよう」と無駄に不安になっていました。
大学によってはWESなどの公式機関でGPA換算を算出するよう勧めているところもありますが、料金や時間的な問題から私はこれについては見送りました。出願時は成績表と同じファイルに(もしくはsupplementary material)にTranscript Legend(それぞれの評価が何点以上を表すのかを示すもの。ある大学が公開しているTranscript Legend例の資料がわかりやすいかもしれません。)を作成、添付した上で、それに基づいて計算したGPAを記入していました。GPAを重視していると公式サイトに表記した大学からも最終的に合格をいただけたので、少しは功を奏したのかもしれません。
GPAが低い場合に挽回可能か
GPAが4.0スケールだと3.0くらいで複数のトップ校に合格した友人がおり、理由を聞いたところ、「強い研究実績(トップ会議での主著論文が複数本)あったこと」「SoPでなぜGPAが低いのかについて合理的な説明をできたこと(学費を自分で捻出するためにパートタイムで働いており、出席点が付く授業での成績が悪かった等)」を挙げていました。もし学部時代のGPAがあまり高くない場合は研究実績など他の出願書類で光るものを見せてSoPで上手く説明ができればトップ校であっても合格のチャンスはあると思います。
科目名がわかりにくい
ACMの基準に沿った科目名で授業を登録しているアメリカや中国などの大学と異なり、日本の大学では科目名(特に英語での表記)が本来の内容と離れてしまっていることがよくあります*19。また数学系の教科が軒並み「数3」「数学演習」「数B」などあまり情報量のない科目名なのも頭が痛かったです...
私は一応科目名とその内容、担当教官、及び使用した教科書の一覧を作成したのですが、肝心の出願時に添付を忘れてしまいました。おそらく添付しなくても大丈夫だと思うのですが、不安に感じた場合は早めに作り始めておくといいと思います。
Curriculum Vitae (CV)
英語圏では(長い)履歴書のことを慣例的にCurriculum Vitae (CV)と呼びます。CVについては少し日本の履歴書と書き方が異なるので戸惑うかもしれませんが、ウェブサイトで英文履歴書を公開している博士学生*20も多いので、自分が行きたい研究室の学生(特に博士課程の1年生等だと出願時と大体同じ内容が確認できるのではないでしょうか)の履歴書をいくつか見てみてどんな構成がいいのか調べてみてもいいのかもしれません。 これについてもSoPと同様、アメリカの大学院に知り合いがいれば体裁や構成等確認してもらうといいと思います。
CVは誤字脱字などがないか、出願フォームでの記入内容と齟齬がないか、見やすいかは大切ですが、基本的にCV自体に時間をかけるよりは、やはりCVに書く内容(研究実績など)を充実させることがより重要です。
推薦状
推薦状は出願において一番重要なファクターとも言われており、可能な限り「強い」推薦状を書いてもらえるように戦略的に頑張りましょう。
誰にお願いすればいいのか
誰に推薦してもらうかについては、以下のような点を考慮して検討すると良いのではないかと思います。
- 研究プロジェクトに一緒に取り組んだことがあるか
- 出願予定の大学のファカルティと直接の知り合いである、もしくは知られているか
- それぞれ異なるプロジェクトで関わっているか、もしくは異なる側面から被推薦者のことを推薦できるか
- 普段英語でコミュニケーションを取っている、もしくはこれまでの国際学会での発表を見ており、英語プレゼンなどの英語能力について評価ができるか
学部からの出願の場合、「卒論の指導教官」「授業のプロジェクト等でかかわった先生」「良い成績(A+)等をとれた授業の先生」に頼む等が多いと思いますが、できるだけ一緒に研究をしたことがある(かつ高く評価してくれそうな)方に推薦状を書いてもらうとより強力だと思います。 学部の早い段階から研究室や民間研究所で研究インターンなどさせてもらえないか頼む、研究室が複数人の先生で運営されている研究室で卒論研究をするなど考えてもよいのかもしれません。
また推薦状はその学生の能力証明という側面も強いので、例えば出願先のファカルティにも知られている方からの推薦状であればより信頼度が高くなると思います。
更に複数の推薦者が全く同じプロジェクトについて同じような側面から言及するよりは、全く違うプロジェクトで関わった所属の異なる複数の先生にお願いする方がより効果的だと思います。もし仮に複数の推薦者にある1つのプロジェクト(卒業研究など)について言及してもらう場合、よりシニアの推薦者には研究全体のことを、よりジュニアの推薦者にはテクニカルな側面(実装能力など)に言及してもらうなど、異なる側面に焦点を当ててもらうよう頼むのが良いのではないでしょうか。
また可能であれば日本人以外の推薦者が一人はいると、英語でのコミュニケーション能力などについても言及してもらうことができます。また推薦者が全員日本人の場合でも、国際学会での発表態度や研究室の留学生とのディスカッションの様子などに言及し、研究に必要な英語能力があると保証してもらえるといいのではないかと思います(特にTOEFLのスコアが振るわない場合)。
機械学習分野での博士課程進学に関するブログで具体的にどういった推薦状が「強い・良い・弱い・悪い」のか書いてくれている記事があり、こちらも参考にするとよいと思います。
推薦状の執筆に際して推薦者に送った資料
私の場合は特に下書きの作成などを推薦者からお願いされることはなかったのですが、執筆を依頼する際には以下の書類をまとめて送っていました。
- CV
- SOP
- (推薦者と取り組んだ)研究プロジェクトの論文及び詳細の英文でのまとめ
最後の「詳細のまとめ」に関してですが、彼らと共に行ったそれぞれのプロジェクトについて「どういう研究を、どういうモチベーションで取り組み、その中で自分はどんな貢献をし、どういった結果となったか」を具体的にまとめました。 またその他に書いてほしいこと(学業成績や分野に関連したボランティア活動、研究室運営に関する貢献など)がある場合についても詳細をまとめて送りました。 これについては正直どの程度役に立ったのかはわからないのですが、私自身SoPを書く際などに振り返りやすくよかったです。またSoPと推薦状の記述内容に齟齬があると心象が悪いので、そのすり合わせも兼ねてこれらの資料はきちんと推薦者に送りましょう。 実際に作成した資料などが気になる方はメールかツイッターなどで問い合わせてください。
また特に学部生の出願の場合、推薦状でどういった内容が書いてあることが望ましいのかと出願先の先生に聞いた際には、
機械学習分野では学部生でのトップ会議発表例も増えているものの、実際には博士課程の学生等が研究の大部分を行っているなどの例も散見するため、研究のどの程度の割合をその学生が行ったのか、についてはっきりと推薦者が明記していると良い。
という回答をいただいたこともあり、推薦状で具体的なエピソードなども交えて自分が研究のどの部分に貢献したのか、はっきりと言及してもらうといいと思います。
大学や先生によってはホームページで求める学生を明記していたりすることもあるので*21、少しそれに合わせて書いてもらうようにしてもいいのかもしれません。
推薦状の依頼・提出
推薦状の依頼に関してはできるだけ早く(遅くとも出願する年の夏)には行いましょう。
推薦状に関してはほとんどの大学で出願フォームで推薦者を登録すると自動的に推薦状をPDF形式で提出するためのリンクもしくはフォームが送信されるような形式になっています。推薦状を書いていただける方に迷惑をかけないよう、出願校が決まり最低限推薦者の登録を行い、早めに提出のためのリンクをお送りしましょう。
Statement of Purpose (SoP)
「SoPは合否に対して影響がない」?
SoPは実際には大して重要ではないと噂もありますが、個人的にいくつかの大学のファカルティやPhDの方と話をした際の印象だと、やはりSoPもある程度重要なファクターであるような気がします。
一般に出願にもっとも重要だと言われるのは(発表論文などの研究実績を除くと)推薦状と言われていますが、先生によってはSoPも推薦状と同様もしくはそれ以上に重視すると公言されていた方もいました。
SoPを読めばその人間がどの程度この研究分野を理解しているか、論理的な文章が構成できるか、研究に対して強いモチベーションやビジョンがあるかどうかが読み取れる。また文法ミスやあまりにも構成が練られていないSoPは印象が悪く、他の出願書類が優れていても受け入れたいとあまり思わない。
また上述の通り、出願時に「弱み」となるような要素がある(GPAが悪い、学部・修士の間に空白期間がある等)はSoPで合理的な利用を述べることができれば減点を小さくできる可能性も高いです。
どんな内容を含めるべきなのか
SoPについては「全ての大学で使いまわせる内容」と「それぞれの大学によってカスタマイズすべき内容」をそれぞれ作成し、前者については早めに作成して友人や先生に内容を早めに確認してもらい、構成を練ると良いと思います。
全ての大学で(大体)使いまわせる内容
- 長期的な研究目標は何か。
- なぜこの研究分野に興味を持ったのか。
- 博士課程では特にどんなテーマに取り組みたいか。
- これまでどのような研究に取り組んできたのか。
- (もしあれば)リーダーシップ活動やハッカソン、競技プログラミングなどの業績
- (もしあれば)エンジニアリングインターンシップや開発経験のアピール
- (もしあれば)国内奨学金などの支援を受けられること
- 博士課程に進学したい理由は何か。
- 博士課程終了後のキャリアプラン(アカデミアに残るのか、企業の研究所などに就職したいのか)
それぞれの大学ごとに修正したほうがいい内容
- なぜ「この大学で」博士課程に進学したいのか。
- 特にどの先生のどんな研究に興味を感じているのか。
これまでの研究経験について説明する部分では「個別の研究においてきちんとモチベーションを明確にする(なぜその研究に取り組みたいと思ったか)」と「それぞれの研究間でのつながりを明確にする」と良いと思います。私は出願時までに行っていた研究の分野がかなり散らばっていたこともあり、CVや論文リストだけ見ると研究興味がはっきりしていないという印象を受けるだろうなと思っていたので上手くストーリーをつなげることを意識しました。またそれぞれの研究プロジェクトにおける自分の貢献を明確にすることも重要です。
またこれは私もわかっていなかったのですが、例えば情報系の分野に関連した課外活動(私の場合は情報科学におけるダイバーシティ推進のための大学生向けのイベント主催したり、女子中高生向けのイベントに登壇したりしました)や開発経験(昔はエンジニア就職希望だったので、積極的に開発系のインターンをしたり、ハッカソンに出場していました)なども、一見研究のステートメントは関係なさそうですが、意外と他の候補者と比べてユニークだと評価してもらえることがあります*22。
どんな内容を含めるべきではないのか
逆に含めるべきではない内容についても言及されている先生もいらっしゃいます。
またコンピュータサイエンスではないですが、実際に「悪い」SoPの例もネットで公開されています。
https://www.niu.edu/engagedlearning/_pdfs/grad-school/PREP-Statement-of-Purpose-Bad-Example.pdf
これらに共通する内容として、「子供の頃からこの分野に興味があり...」「初めてコンピュータを触ったのは...」などの記述です。これらの内容はそれが現在の研究興味やPhD進学を希望する理由に直接関わっていない限り、避けた方が無難です。基本的には「研究経験や興味、研究に関連する技能や知識、もしくはアウトリーチ活動などを通して大学というコミュニティに貢献できること」であるかどうかを基準に含めるべき内容を書くといいと思います。
以下のサイトではより形式的にどういった誤りを避けるべきかについて紹介されています。
参考にした資料
ネットで過去に出願した方のSoP*23や「SoPの書き方」のような書籍もあるのですが、私が執筆に関して一番参考にしたのは志望度の高い2校の博士課程に在籍している(いた)方々からいただいた、彼らの出願時のSoPでした。 日本にいて実際に北米の大学院にいる方とコンタクトをとるのはハードルが高いですが、知り合いのつてをたどったり、もしくはメールをお送りしてSoPや出願に関して相談させていただきました。 私のSoPについても連絡いただければお送りします(ただ過去の出願者とあまりに酷似しているとそれだけで剽窃を疑われて落とされかねないので、参考程度にするのがよいと思います)。
執筆手順(スケジュール)
私は以下のような手順でSoPを執筆しました。
- ネットなどで大まかにどういう内容を書くべきなのか等の資料を収集する(9月上旬)。
- 出願予定の大学院に在籍している博士学生から出願時のSoPをもらう(9月下旬)。
- 執筆を開始する(10月上旬)。
- 先生や北米大学院の博士課程に在籍している(いた)友人に第一稿を確認してもらう(11月上旬)。
- もらったコメントをもとに修正し、これを繰り返す(11月中旬〜12月上旬)。
- 大学ごとの段落を作成する(11月下旬)。
- 英文校正に出す(12月上旬)。校正後のSoPを再度友人に内容を添削してもらう。
- 体裁を整えて提出(12月上旬〜中旬)。
繰り返しになってしまいますが、SoPに関しては誤字・脱字は絶対に排除しましょう。 また文法チェックなどはGrammarly有料版だけでは心許ないので、できればネイティブの友人の添削や英文校正に出しましょう。
私は英文校正に関しては Graduate School Application Editing - Fast and Affordable | Scribendiを利用しました。proof readingは構成などはそのままで、文法チェックや言い回しの修正を中心に行うもので、editingは構成なども含め大幅なサジェスチョンを行ってくれます。また要望欄に「~words以下にしてほしいから短くできそうなところは短くしてほしい」と書くと冗長な言い回しの削除やより簡潔な言い回しにしてくれます。 英文校正サービスで添削してくれる方は自分の専門分野が専門でないことが多いので、理想的には「英文校正サービスの添削+同じ分野を専門にするネィテイブの友人の添削」の両方を行うのがいいのではないかと思います。
友人らに英文添削をお願いする場合は、(かなり細かい話ですが)アメリカ英語かイギリス英語に統一する、カナダ英語などが突然登場しないように気をつけた方が無難だと思います*24。
面接
情報系では一般的に他の分野ほど選考過程で面接が行われない*25という話もあるのですが、私の場合は北米は出願した11校のうち、9校から面接オファーがありました。
最初の面接のオファーが来てから2日後に面接が予定されていたので、慌てて想定問答集みたいなものを用意し、友人に擬似面接をしてもらいました。
面接といっても大学によって位置づけが大きく違うようで、先生と具体的にお互いのリサーチの興味がマッチしているかかなり突っ込んだ話をする面接(このタイプの面接は合否に特に大きな影響を与えるので、慎重に準備をした方が良いと思います。)と、フランクに志望する先生のグループの博士学生と話す面接がありました。ちなみに詳細は割愛しますが、かなりテクニカルな質問(このモデルにおけるメモリや計算量的な意味でのボトルネックは何か等)をされたりすることもあります。
面接でよく聞かれるトピック
これまでの研究経験について
まず最初に「あなたの過去の研究の中で一番気に入っているものを説明してください」「一番最近の研究を説明してください」等を聞かれることが多いと思います。
自分の過去の研究、特に直近の研究やSoPで大きくページを割いて言及している研究についてはきちんと自分の中で以下のような点を整理していくといいと思います。
- その研究のモチベーションは何か。ゴールはどこにあるのか。
- どのような解決策を提案し、それはこれまでの手法と比べてどのような独自性があるのか。
- 結果はどうだったか(従来手法と比べて大幅な性能改善など)。また面白い発見はあったか。
- その研究の中で自分はどのような役割を果たしたか(実装のこの部分をおこなった、論文を主著者として書いたなど)。
- この研究をするうえで何が困難であったか、どうその困難を克服したか。
博士課程でやりたいテーマについて
余程の理由がなければSoPと大体同じ内容を言い換えたり少しアイディアを補足して説明するといいと思います。
なぜこの大学なのか
余程の理由がなければSoPと大体同じ内容を言い換えたり少しアイディアを補足して説明するといいと思います。また面接相手がSoPで名前を挙げた先生であるならば、「あなたの研究内容に興味があったから」等を直接伝えてもよいと思います。
博士課程を卒業した後何をしたいか
おそらくこれもSoPとほぼ同じ内容を応えるといいと思います。理論立った説明をできる場合を除き、SoPと食い違う内容を回答するのは得策ではないかもしれません。
最近読んで面白かった、もしくはこれまで読んだ中で一番面白かった論文は何か
これは候補者が実際に先生の研究の興味とマッチしているかを確認するために聞かれるケースが多いような気がします。あまりにもその先生の興味がなさそうな分野・論文をピックアップしてしまうと、研究興味が合わないのでは…?という印象を与えてしまう印象があります。一方でその先生がじっくり読んでいそうな分野のものを選んで見当違いな説明をしてしまってもよくないのでバランスが重要そうです…
私は自分が読んで面白かった論文のうち、特に面接をしてくれる先生が興味を持ちそうなものを一つ選び、
- 簡単な要約
- なぜ面白いと感じたか、自分の研究興味をどう関連するのか
についてのメモを作成していました。
何か質問はあるか
企業の面接などでも最後によく聞かえれることですが、できる限り「特にないです」等と答えるのはやめましょう…
相手がSoPで名前を挙げた先生ならば彼彼女の現在の方向性や今一番熱意をもって取り組んでいる研究課題などを聞くと、もし仮に自分がその大学に入学した場合にどういった研究に取り組むことになるのかなどもわかっていいと思います。また学生にどんな素養を求めているか、というような話も聞いたりしました。
ちょっと特殊な質問例
上述の質問はどの大学でも割と聞かれるのですが、それ以外にも先生によって少しずつ違うことを聞いたりします。
- データセットを新たに作るような研究と手法を既存のデータセット上で改善していくような研究のどちらがやりたいか
- 研究のどんな部分が一番好きか
- どのようなスタイルで研究するのが好きか
- 大きな研究グループで研究するのが好きか、少人数の研究グループで研究を行うのが好きか
- 研究に関することであなたの強みと弱みは何か
- どんな指導方法を期待するか
- 研究をしていて最も面白いと感じる瞬間はいつか
- 研究をしていて一番大変だと感じる瞬間はいつか
- これまでの研究の中で、もっとも分野に対してインパクトの大きい貢献をできたと思う部分は何か
合格可能性を上げるためにした方が良いこと
事前コンタクト
事前コンタクトをとる利点
アメリカの大学院、特にCS系の場合、合否の決定がアドミッションコミッティーによって決定されるから事前のコンタクトは特に意味がない、もしくは教授が大量にメールを送られてくる*26から反応すらしないことが多い、という話も聞きます。
ただ実際には(その教授がアドミッションコミッティにいるいないに関わらず)学部に所属する教授がコミッティへ特定の出願者を「推薦」することは一般的に行われ、合否決定である程度考慮されるようです。そのため、志望大学の教授に「一緒に研究したい、研究グループで獲得したい」と思ってもらえると合格可能性はかなり高くなると思います。
事前コンタクトをとる利点として
- そもそも返信をくれるかどうかである程度自分に対して関心があるか判断ができる*27。
- 学生を今年とらない予定だ、などの情報を事前に知ることができる。
- 上手く研究興味がマッチしていると思ってもらった場合に、出願後に後日声をかけてもらえたりする。
- 出願先の学生と知り合うことができ、出願時にその学生に面倒を見てもらえたりする。
- 出願数が急増する中で出願書類を見落とされてしまうリスクを減らすことができる。
個人的にはTOEFLなどの足切り点は既に超えており*28、かつ国際会議での発表などある程度の研究実績等がある場合は事前にコンタクトできないか挑戦してみる価値は十分にあると思います。
もし可能であればメールを送るだけでなく、直接訪問する、スカイプでミーティングするなど、30分から1時間程度直接話す時間を作ってもらえないか挑戦してみるといいかもしれません(特に学部生などで目立った研究実績がない場合)。
どのようなメールを送るべきか
最初に送るメールはできるだけ簡潔に、かつ自分のこれまでの研究業績や研究興味、そして特に「なぜあなたのところで研究したいのか」がしっかり伝わるといいと思います。
私は毎回その先生の過去2年の論文のうち、特に自分の博士課程の研究興味に近く面白いと思えた論文に言及し、「こういった点であなたの論文が面白いと強く感じ、あなたの指導のもとで博士課程の研究を進めたいと思っている」と書いていました。 またメールに長々と業績を列挙するのではなく、「CVつけたので見てね!」とCVをメールに添付するといいと思います。
It's "pre-grad-admission inquiry" season, so here's a useful tip if you must send this sort of email (for what it's worth, none of my current students sent me one before they applied): pic.twitter.com/7b79if8UBJ
— Tal Linzen (@tallinzen) 2019年10月29日
バージニア大学のCSの先生が書いたコンタクトの仕方についてのブログ記事を参考にメールを作成し、博士課程に在籍している友人に添削をしてもらいました。 www.cs.virginia.edu
ただ、このQuoraの回答にもあるように、宛名だけ変えたようなテンプレートな文面を送るとかえって逆効果になりかねません。
I get a lot of letters of this type. Let me tell you what NOT to do. The first contact should not be a spam letter -- that is, a letter that you could easily have sent to 1000 faculty members worldwide, and probably did. Why should I spend more time answering your letter or reading your resume/CV than you spent writing the letter?
どのタイミングで連絡すべきか
出願時期が近付くほど、出願予定者からの連絡が増えると思うので、おそらく8月ないし9月くらいまでには一度連絡できるといいのではないでしょうか(私はこの時期に連絡した方からは9割くらいの確率で返信をいただけました)。 それより早くてもいいかもしれませんが、博士での研究テーマが曖昧なままディスカッションすると逆に悪い印象を与えるリスクもあるので、自分の中である程度SoPで書くであろう内容についてアイディアがまとまってから連絡しました。
また出願後にも「出願した報告+前回話したときからのアップデート(奨学金の採択報告、論文投稿ないし採択報告)」をすると、より効果的ではないかと思います。
国内奨学金
CSの場合、一部の専攻(軍事的な側面から一部のFellowshipに外国人は応募できないなどの制約がある分野)に比べると若干アドミッションへの影響は少ないのかもしれませんが、やはり国内奨学金を獲得していることはかなり重要です。
ある先生は
国内などで支給される奨学金を持っていることは大変いいと思う。やっぱり奨学金をある程度持ってきてもらえると教員側としては負担が減るので安心する。またこの国出身の学生の中で特に優秀な学生なのだという保証にもなる。
と仰っていました。 「最近は人工知能ブームで関連分野の研究室は資金が潤沢だから奨学金を自分で持ってくる必要はない」「大学からFellowship・TAもしくはRAが出るから必要ない」という噂もあるのですが、
現在かなり資金が潤沢なので、奨学金の有無で自分のなかで学生の順位づけが変わることはない。例えば二人の学生AとBがいて、業績などからAの方が優秀だと思えばBが最初2年間すべてをカバーする奨学金を持っていてもAを取る。ただAとBが同程度だと思った場合は、奨学金があるBを取る。
というのをある大学の先生(周辺企業からの研究資金を大量に獲得している)から伺ったことがあるので、やはり合格の可能性を少しでも上げたい場合は奨学金を獲得すべきだと思います。
また奨学金を持っているとTAおよびRA業務で自分の研究時間が削られるということも少し減ると思うので、そういった意味でも奨学金を獲得するメリットは大きいと思います。
私が出願した国内奨学金
私は以下の奨学金に応募しました。 運もあるのでできる限り多くの奨学金に申し込むのがいいと思います。
国内奨学金出願に関する注意点
国内奨学金は東京などで開催される面接に直接参加すること(Skype参加はNG)、申請書類は郵送(必着と当日消印有効を勘違いしないように気を付けましょう)、手書き必須(平和中島、伊藤国際等)、TOEFLの正式なスコアレポートの写しが必要(オンラインで確認できるレポートはNG)などがあるので、それぞれの奨学金の応募要項をよくチェックしましょう。スコアレポートが手元にない場合、ETSのサイトから申請する必要があり、2週間程度発送にかかるので遅くとも7月には手元に正式なスコアレポートがあるか確認しましょう。
また日本の財団系奨学金ではあまりないものの、「卒業後日本に帰国する、もしくは日本企業などに就職する」などを受給条件としている奨学金も一部存在します。 博士号取得後絶対に日本に帰国したいという意思がない限り、こういった点についても申請時に慎重に検討しましょう。 先生によってはこの「帰国義務」を心配する方もいるので、仮に帰国義務のない奨学金に採択いただき、面接で奨学金の話を言及された場合ははっきりとこの点を強調するとさらに好意的に見てもらえると思います*29。
また大学院出願前(遅くとも11月末まで)に採択通知が受け取れそうかどうかも確認しましょう。大学院出願時は正式な証明書(PDF版)を提出する必要があるので、採択されたあとはなるべく早く正式な証明書の発行(及び可能であればPDF版の送付)を財団に依頼しましょう。
これまで質問されたこと
学部から直接PhDに出願するべきか
日本からアメリカの博士課程に出願する場合、「日本で修士課程に進学してからの出願」もしくは「学部から博士課程にそのまま出願する」の大きく分けて2つのパターンがあります。学部からの出願の場合、「準備期間が短い」「修士を卒業後(研究員などを経て)博士進学した博士学生と比較し経験や知識で差がある」というデメリットはあるものの、「(ある程度の研究実績があれば)ポテンシャルをより評価してもらえる」「日本で修士課程を過ごす時間・費用を節約できる」などのメリットも大きいと思います。
また、昨今「人工知能」と纏められる分野ではかなり博士課程の競争が過熱化しており、トップ会議論文が複数本なくては合格は難しいと言われています。しかし実際にはこういったパブリケーションに対する基準・評価は候補者のバックグラウンドに応じて異なり、学部からの出願者だと出願時に一本でもこれらのトップ会議で主著論文があるもしくは2nd Tier・ワークショップ論文があればある程度評価してもらえるようでした。一方で確かに修士以降からの出願だとトップ会議 (機械学習やNLP、CV分野ではACL, CVPR, NeurIPS, ICLR, AAAIなど) ですでに主著論文が複数ある候補者が多く、パブリケーションでの差別化が困難になっていそうです。学部3年生の終わりまでに2nd Tier会議やワークショップ論文などでも実績が作れた場合には、敢えて学部から直接出願する、という選択肢もあると思います。
余談ですが、現在著名な大学のCS博士課程には毎年1500~2000程度の出願があり*30、 特に人工知能領域(機械学習、自然言語処理、コンピュータービジョン)はかなり厳しい状況*31です…
非情報系からの情報系の博士課程への出願
仮に現在の専攻が情報系でない(物理・数学・統計・言語学・電気工学・機械工学等)でも出願は可能な場合が多く、特に学部時代に情報系の科目を履修し良い成績を納めていたり、研究内容がこれらの分野と関連していたり、研究実績に優れていた場合は十分に合格が可能*32です。ただやはり出願への時間的な猶予なども考えると、一旦国内もしくはアメリカの情報系の修士へ出願し、修士課程の授業を履修しつつ研究経験を積んでから博士課程に出願する方が可能性としては高いのかもしれません。
またどうしても学部から博士課程に直接出願したい場合、学部在学中に転学部などで情報系の専攻に変わることも選択肢としてあると思います。 私はもともと東京大学へは文科(文科2類)で入学し、一度進学振り分けで経済学部に進学したのち、留学を経て工学部電子情報工学科に転学部をしました。そのため前期教養で数学や物理系の授業の履修が少ないことやそれにより基礎的な数学・物理の素養がないと判断されるのではないかと出願時期に心配していました。 実際に出願した先生に合格をいただいた後聞いたところ、私の場合は推薦者がこういったバックグラウンドに言及した上でとても好意的に評価をしてくれていたこと、専門課程(特にCS系)での成績が良かったこと、開発インターンやハッカソンでの受賞歴などがあり、プログラミング能力が評価されていたなどの点から、ポジティブに解釈されたとおっしゃっていました。
異なるバックグラウンドからの出願は不利に働く可能性もありますが、好意的に評価されることもあるため、気後れせず出願について検討するといいのではないかと思います。
(学部からの出願の場合)現在の所属大学の院試は受けるべきか
学部から直接アメリカの博士課程に進学する場合、所属大学の修士課程への出願を同時にすることは、合格すればアメリカの大学院全てに落ちても所属大学の修士課程に進学できるという安心感があるなどのメリットがある一方で、院試勉強にどうしてもある程度時間が取られるというデメリットがあります。
私の所属していた電子情報工学科は多くの学生が東大の情報理工学系研究科(電子情報学専攻、コンピュータ科学専攻、創造情報学専攻など)に進学するのですが、内部生推薦などはなく、学科同期もだいたい1〜3ヶ月程度試験勉強をしている人が多かったです。私はもともと情報理工も受験するつもりで出願をしましたが、秋からの北京でのインターンの準備、並行して行なっていた2つの研究、アメリカ大学院出願関連の準備と所属大学の院試勉強でキャパオーバーになり、大きく体調を崩し結局未受験となってしまいました(出願料…)。
院試勉強にかなり時間を取られそうな場合は、メリット・デメリットを慎重に検討した方が良いと思います。修士課程への内部推薦制度があるならば積極的に活用していくと良いと思います。
出身大学名はどの程度考慮されるのか
専門や出願年よって大きく状況は変わると思いますが、現在特に競争が過熱しているAIなどの分野では出身大学(特に学部を卒業した大学)をある程度スクリーニング時に見ているような気がします。もちろんこれはパブリケーションなどの実績で十分補うことが可能ですが、学部から出願するか、修士以降から出願するかなどの違いとも併せて、アメリカの博士課程出願は出願者のバックグラウンドに応じて同じような研究業績でも基準・評価が変動する点は十分注意が必要です。
あるPh.D.学生が書いた記事では、彼が自分の合格したあるトップ校の学生に調査を行ったところ、学部がアメリカ国内のトップ校の場合はパブリケーションが1つ以上であれば合格可能性がある程度高いのに対し、学部がアメリカのトップ未満もしくは各国のトップ校の場合は2本以上、そしてそれ以外の場合は3本以上となっています。またパブリケーションが複数本なくとも、アメリカのトップ校の修士課程(CMU, Stanfordなど)を経てから出願すれば合格可能性があるともしています。
参考になるブログなど
私は出願時にはこれまでにPhD出願をされた方のブログ(体験記)や審査側の先生や学生が公開している情報がとても参考になったので、こちらに紹介させていただきます。
受験者の体験記
アメリカ大学院PhDプログラム出願に必要なもの : 筑波大学からコーネル大学博士課程に進学したもうせくんの出願に関してのブログ。学部からの出願者にとって大変参考になると思います。
Awaken the power to apply for Ph.D. programs : 東大の電気電子・電子情報工学科の先輩であり、今年UWの航空宇宙専攻に進学される越後さんによる大学院出願に関するブログです。詳細に出願準備を説明されており、CSでの出願時にも役に立つ情報も多いです。
JHU: 出願準備〜Offer取得までの記録 : 昨年JHUで博士課程を修了された坂口さんのブログ。私自身もともと文系バックグラウンドなこともあり、とても励まされました。
船井情報科学振興財団 これまでの奨学生: 船井財団の奨学金は奨学生の方が定期的に留学報告書を投稿されており、初回は留学準備や出願に関して詳しい投稿をしていただく方も多いので、とても参考になりました。 私は専門分野の近い、川上さん、笠井さん、胡さん、林さん、大谷さんの過去のレポートを特に参考にさせていただきました。同じ情報系でない方の留学体験記なども目を通すと思わぬ発見があると思います。
Student Perspectives on Applying to NLP PhD Programs: NLP分野のPhD1, 2年生10人余りに出願に関してアンケートを行い、集約したもの。NLPに限らずAI分野の学生にとっては参考になる情報も多いと思います。
Machine Learning PhD Applications — Everything You Need to Know: UW CSEの博士学生によるブログ。日本からの出願限定ではないものの、機械学習や関連する応用分野での最近の博士課程出願に関してはおそらく一番参考になるのではないでしょうか。「出願者のパブリケーションレコードのインフレが発生しており、フルペーパーなしでの合格は難しい」「出身大学によるフィルタリングが存在すること」という耳が痛くなることも多く指摘されていますが、この分野で博士課程オファーを獲得しようと考えているならば是非一読いただきたい内容です。
2020冬 - 専門別:コンピューターサイエンス - 海外大学院留学説明会: 先日行われた小ンピュータサイエンス分野に特化した博士課程留学に関しての講演会やパネルのYoutubeビデオ。私も参加しています。私以外にMIT博士課程の五十嵐祐花さん、ベルリンにあるHasso Plattner Instituteの茂山丈太郎さん、Oxfordを卒業し現在国立情報学研究所助教の五十嵐歩美さんと大学院出願や博士課程での経験、Covid下での研究など様々なトピックについて話しています。
アドミッション関係者の公開している資料
Applying to Ph.D. Programs in Computer Science: CMUやUC Berkeleyなどでアドミッションに関わったCMU CS教授による包括的な資料
Answers for Prospective Graduate Students: NLPの著名研究者でJHU CSの教授であるJason Eisner氏による、アドミションでどういった点を考慮するかについてのブログ記事。
Demystifying the American Graduate Admissions Process: Staford CSのアドミッションに関わっていた学生による資料。Master出願がメインなので一部PhD出願と異なる部分も多いですが、どういうシステムで専攻が進むのか、というプロセスについてはPhDとある程度共通しており参考になると思います。
Admission Statistics (UW Graduate Schools) ワシントン大学の大学院の全専攻におけるアドミッション統計(出願者数、合格者数、実際の進学者数またその性別、留学生かどうか)。Computer Science and Engineering の博士課程の出願者が他の専攻と比較してかなり多く、International applicantsの合格率が6%程度であることがわかります...
これまでの過去全ての統計はこちらのページからアクセスできます。UPenn CIS Admission Statisticsペンシルベニア大学の出願者数、合格者数、進学者数及び合格者のGREスコアの平均データ。
質問など
学期中はあまりすぐ返信などできないかもしれませんが、質問などある方はTwitterかメールでコンタクトいただけると幸いです。
Email: akari@cs.washington.edu
*1:もちろん修士課程に進学してから博士課程に進学するケースもあります
*2:ちなみに一部の大学ではアメリカ外の大学の「トップ校ランキング」を独自に作成し、それに基づいて評価を行なっているようです。ちなみに少し前まである大学の内部リストでは日本の大学は1つも掲載されていなかったようです...
*3:この時点ではGREやTOEFLなどのスコアはもう見なくなる大学と、一応GREのAWやQuant、TOEFL Writingなど研究に関連するスコアについても再度確認する大学があるようです
*4:おそらくこの時点でも候補者プールには数百程度残っているので、特定の教授と働きたい場合はここできちんと名前を言及しないと見落とされる可能性が高いです
*5:主に合否ラインに載っている場合に行われることが多いです。面接まで行けば合格可能性は半々くらいではないでしょうか。信憑性は定かではないですが、今年のスタンフォードは上位10~20パーセントの学生のうち、合格を出すことが確実なトップ数パーセント層を除いて短い面接を行ったようです。
*6:この際に推薦した教授が将来的にアドバイザーになることが多いようです
*7:一応ホームページには必須ではない旨が書いてあるのですが、「同程度の候補者がいた場合はビデオエッセイを提出した方を優先して合格させる」と公式も書いており、また今年は更に2月ごろに急遽ビデオエッセイの提出を要求する連絡を受け取った候補者もいたらしく、よほどの理由がない限りこのプログラムに関してはビデオエッセイを提出すべきだと思います。
*8:おそらくStanfordなどのトップ校では本当に足切れすれすれのスコアです…。時間があるならばきちんと準備をして320後半を取るべきだとは思います。ちなみにある大学の関係者には「今年の自然言語処理分野の合格者は(君以外)ほぼGREで満点だったよw」と言われました…
*9:UWの場合、26点に届かなくても23点以上であれば面接によりSpeaking能力をアピールできればTA業務に従事できます。裏を返すとSpeakingのスコアが23点より大幅に低いとやはり代替措置も難しくなるため、足切りをされてしまう可能性はかなり高いと思います... https://grad.uw.edu/policies-procedures/graduate-school-memoranda/memo-15-conditions-of-appointment-for-tas-who-are-not-native-speakers-of-english/
*10:ただカナダの大学の一部では学部からの出願場合必ずまず修士プログラムに出願する必要があり、修士プログラムについては明確に(事実上の)ミニマムスコアが設定されていることがあります。マギル大では「Applications with less than 3.5 in the analytical section or less than 160 quantitative are very unlikely to be accepted. Weak verbal reasoning scores may also contribute to refusal of an application.」としています。
*11:ただ大学によっては100超えていれば全く気にしないという声もあるので、あくまで余裕があればだと思います。
*12:https://www.cs.cmu.edu/~harchol/gradschooltalk.pdf
*13:私はTOEFLのSpeakingが22と振るわなかったのですが、アメリカ人の推薦者が「彼女の英語のプレゼンテーションスキル、コミュニーケーションスキルは極めて高い」など書いてくれたようです
*14:http://gakuiryugaku.net/web/wp-content/uploads/2017/03/panel_noda.pdf
*15:実際トップ校のPhDプログラムに学部から直接合格したPhD学生のCVなどを見ると、学部成績がかなり上位であるsumma cum laudeや100名を超える同級生の中で首席で卒業した、などの記述がある学人がかなり多いです。
*16:いくつかの大学では学部全体でのGPAと専門科目でのGPAの両方を記入するよう求められました。UWでは直近の60単位でのGPAをわざわざ記入させる欄がありました。
*17:https://www.cs.ucla.edu/graduate-admission-requirements/
*18:http://timdettmers.com/2018/11/26/phd-applications/
*19:音声・自然言語処理が「Spoken And Written Language Information Processing」だった時はびっくりしました...
*20:ウェブサイトでCVと書いてあるセクションに行くと大抵彼らの最新のCVが確認できます
*21:先生のホームページにProspective StudentやJoin our group?等書いてあるページがあれば事前コンタクトに関することや学生をとるかどうか、求める学生像など明記している場合が多いです
*22:私は出願先の大学院生に確認してもらった際、ダイバーシティ推進のための活動やハッカソンで作ってきたプロダクトに関する段落について、「他の候補者と差別化できる点だし、多様性を重要視する大学の審査では好印象を与えると思うので、絶対にこの部分は削らないほうがいい」と言われました。
*23:http://www.pgbovine.net/PhD-applications/Philip_Guo-Stanford-PhD-app-statement.pdf
*24:話し言葉や発音と比べると、フォーマルなライティングにおける差は小さいと思いますが、analyze/analyseやcentre/centerなど意外とSoPで使いそうな単語でもスペリングが違ったりします
*25:CSによっても面接をどの程度行うかは大学によります。Do PhD admissions for computer science usually have interviews? - Quora
*26:知り合いの教授は毎日20通近いメールが「Prospective Student」から送られてくると言っていました…
*27:実際ある先生は「メールが来たらメールと添付されている資料などを見て、実際にあったりメールに返信するか決めている」とおっしゃっていました
*28:足切りを超えていない場合、そもそも教授まで応募書類が届かないことが多いです…
*29:私は実際に面接である先生から、「奨学金持っているのはとても良いと思うんだけど、これは博士号取得後に日本に帰る義務があるの?」と聞かれました
*30:今年のCornell CS PhDが出願者が1452、UWが去年に引き続き2000超だったようです。
*31:NLPと音声に特化したCMU CSのLTIプログラム単体で700程度、機械学習の理論的な分野をメインに据えるCMU CS MLDで1000程度の出願があったようです
*32:もちろんこれは私の専門分野がCSの中でも言語学や統計、数学に近い自然言語処理・機械学習のためバイアスがかかっていることも否定できませんが…
Word2Vecモデルをスクラッチで実装してみる ② 基本のNeural Netの実装
このブログは情報系を勉強する女子大生 Advent Calendar 2017 - Qiitaの17日目の記事です。
内容としては
Word2Vecモデルをスクラッチで実装してみる ① そもそもWord2Vecって? - あさりさんの作業ログ
の記事の続きになります。
前回はざっくりWord2Vecモデルがどんなものか説明したので、いよいよ実装してみようと思います。
基本的にNumpyを使って実装しました。ちなみに諸事情によりPython2系です。
実際にモデルをStanford Sentiment Treebankのデータで学習させた結果を二次元状にプロットすると
以下の感じになります。

(結果が微妙???キニシナイキニシナイ)
実装にあたっては前回も紹介したスタンフォード大学の
Stanford CS 224N | Natural Language Processing with Deep Learningの授業資料や授業課題を参考にしています。
とても良い授業なのでお正月に暇な方は見てみてください〜 :)
ニューラルネットワーク自体の説明については、自分が拙く行うよりもネットや教科書でとてもわかりやすくまとめてくださっている方がたくさんいるので割愛します。
個人的に日本語でネットで読めるものだと 愛媛大学の村上研究室のニューラルネットワークについての記事の第3, 4, 5章 がわかりやすいと思いました。
この記事では実装や勾配計算、勾配の確認などをざっくりさらっていきたいと思います('-'*)
基本のNeural Netを実装してみる
今回は隠れ層が一層のみのニューラルネットワークを実装してみます。

活性化関数にはシグモイド関数を、出力層にはソフトマックス関数、コスト関数は交差エントロピー損失を用います。
この記事ではまずソフトマックス関数、シグモイド関数、交差エントロピー関数について実装と勾配を計算した後、
順伝播、逆伝播部分の実装を行なって最後に実際に逆伝播の実装に誤りがないか、gradient chekingを行う構成になっています。
ソフトマックス関数を実装する
まずソフトマックス関数を実装してみます。
ソフトマックス関数とは
次元実数ベクトル
を受け取って 以下を満たす
次元実数ベクトル
を返す関数です。
式からもわかるようにソフトマックス関数には
という性質があり、分類問題をニューラルネットワークで解く場合に、出力層の活性化関数として用いられます。
例えば手書き文字画像からその文字が実際にどの数字を指しているのか当てるmnist問題では、
入力が実際に0から9のどの数字になりそうかの確率を出力し、最も確率の高い数字を予測として出力します。
この場合出力層で最後の隠れ層の出力結果をsoftmax関数に通すことで、「全体の合計が1になるかつそれぞれが0から1の間の数字になる」10次元の実数ベクトルが
帰ってくるので、その中で値が最大になるのインデクスが分類予測結果になります。
とりあえず実装してみる
とりあえずnumpyを使ってこのsoftmax関数を実装してみます。
def softmax(x): e_x = np.exp(x) sum_e_x = np.sum(e_x) x = e_x / sum_e_x return x
これみるとちょっとゾワってしません??ちなみにこのコードで適当にsoftmax(np.array([1, 3, 4, 5, 1000]))と入れて実行してみると
オーバーフローのために出力値が不定値になっていることがわかります。
__main__:2: RuntimeWarning: overflow encountered in exp __main__:4: RuntimeWarning: invalid value encountered in true_divide array([ 0., 0., 0., 0., nan])
ちなみにsoftmax(np.array([1, 3,4, 5, 10]))を実行すると、softmax関数によって合計が1になるような実数値のベクトルが出力されていることがわかります。
array([ 1.22157447e-04, 9.02628229e-04, 2.45359791e-03, 6.66957062e-03, 9.89852046e-01])
理由としてはとてもシンプルで、 がxが大きくなると簡単に数値がオーバーフローして不定値になってしまうためです。
試しにnp.exp(1000)を計算してみるとオーバーフローが発生していることが確認できます。
>>> np.exp(1000) __main__:1: RuntimeWarning: overflow encountered in exp
オーバーフローをしないよう最大値を引く
この対策としてよく行われるのが、あらかじめ入力として与えられた実数値ベクトルにおける最大値を引区という方法で、数式で表すと以下のような計算を行うことになります。
ソフトマックス関数の入力に対して定数オフセットを追加しても(この場合は入力から最大の値を引いても)結果は不変になります。
だったりすることを利用して
工学部なのでざっくりと計算してみると、実際に定数を追加した場合も出力結果は不変であることがわかります。
実際に入力から最大値を引いたソフトマックス関数をnumpyで実装してみると以下の通りになります。今後のことも考えて、
入力が次元のベクトルの場合と
のマトリックスである場合両方実装します。
def softmax(x): x = x.astype(np.float64) if len(x.shape) > 1: # Matrix e_x = np.exp(x.T - x.max(1)) x = e_x / e_x.sum(axis=0) x = x.T else: # Vector e_x = np.exp(x - np.max(x)) x = e_x / e_x.sum(axis=0) return x
シグモイド関数及び勾配を計算して実装してみる
次に活性化関数のシグモイド関数の実装について考えてみます。
シグモイド関数は以下の式で表され、 の単調増加連続関数で、1つの変曲点を持つ実関数(つまり
どんな大きな入力が与えられても、小さな入力が与えられても出力結果が0から1の間の実数になる)です。
ソフトマックスの時と同様、numpyを使って実装してみると以下のようになります。
def sigmoid(x): x = np.array(x, dtype=np.float128) s = 1.0 / (1 + np.exp(-x)) return s
学習中のオーバーフロー対策としてとりあえずnp.float128で
キャスティングしているのですが良い子は真似しないでください。
シグモイド関数でのオーバーフロー対策としては値をクリッピングする(np.float64で表現できる値より大きくなる場合は強制的に値を打ち止める)やscipy.special.explitを使う方法があるみたいです。
このシグモイド関数の勾配についても実装します。
シグモイド関数の勾配は商の微分公式など使って計算でき、シグモイド関数の勾配はシグモイド関数の値と1からその値を引いた値との積で表せることがわかります。
このためシグモイド関数の実装はこんな感じでとてもシンプルに書くことができます。
def sigmoid_grad(s): ds = s * (1 - s) return ds
コスト関数(交差エントロピー損失)の勾配を計算して実装する
コスト関数として用いる交差エントロピー損失についても、実装と勾配の計算を行います。
交差エントロピー損失についての説明及びなぜ交差エントロピー損失を使うべきかなどは本やブログで詳細な説明を行っている方もいるのでここでは割愛します。
を正解ラベル、
を予測された結果とすると、交差エントロピー関数は以下のように定義されます。
今回は出力層にsoftmax関数を使っているので となります。
def cross_entropy_loss(y, y_hat): # y = labels, y_hat = softmax(theta) cross_extropy_loss = -1 * np.sum(y * np.log(y_hat)) return cross_extropy_loss
この交差エントロピー損失について、入力についての勾配を計算すると
となるため、単純に正解ラベルと出力結果との差を計算すれば良いことがわかります。
隠れ層一層のニューラルネットワークの勾配を計算する
上で計算・実装したものも組み合わせながら、「隠れ層が1つのニューラルネット」を実装していきます。
まず順伝播部の実装を行います。
上の図の 及び
については次の式で表すことができます。
については二層のウェイト及びバイアスを示しています。
まず入力データ、初期パラメータ、入力層・隠れ層・出力層のデータを入力とし、隠れ層及び出力層の出力を返す
forward_pop()という関数として実装します。
def forward_prop(data, params, dimensions): # dataは入力データ(x) # dimentionsがそれぞれの層の次元を表している。 # paramsは各パラメータの初期値。 # params = np.random.randn((dimensions[0] + 1) * dimensions[1] + (dimensions[1] + 1) * dimensions[2], ) などで初期化 # Dxが入力層の次元、Hが隠れ層の次元、Dyが出力層の次元 ofs = 0 Dx, H, Dy = (dimensions[0], dimensions[1], dimensions[2]) W1 = np.reshape(params[ofs:ofs+ Dx * H], (Dx, H)) # W1.shape = (Dx, H) ofs += Dx * H b1 = np.reshape(params[ofs:ofs + H], (1, H)) # b1.shape = (1, H) ofs += H W2 = np.reshape(params[ofs:ofs + H * Dy], (H, Dy)) # W2.shape = (H, Dy) ofs += H * Dy b2 = np.reshape(params[ofs:ofs + Dy], (1, Dy)) # b1.shape = (1, Dy) h = sigmoid(np.dot(data, W1) + b1) # h.shape = (N, h) y_hat = softmax(np.dot(h, W2) + b2) # y_hat.shape = (N, Dy) return h, y_hat
dataは(N, Dx)の行列で与えられ、paramsは((Dx + 1) * Dx + (H + 1) * Dy, 1)の乱数ベクトルでまとめて与えています。
順伝播を計算する際はこのparamsをそれぞれ適切な形にnp.reshape()でreshapeした後、ドット積・加算などを行い、
先ほど実装したsigmoid, softmaxなどの関数を持ちいてy, y_hatを求めます。
これで順伝播の計算ができたので、逆伝播についても計算して実装してみます。
とおき、コスト関数の入力xについての微分を順に後ろから計算していきます。
基本的には合成関数の微分を使って
を計算していくだけなのですが、一気にやると間違えそうなので一つ一つ微分を計算していきます ('-'*)
(一応ベクトルは太字で区別するようにしているのですが、面倒になって太字化し忘れているところがあるかもしれません。年明けに直します…)
まず交差エントロピー損失関数のについての微分を計算すると、これは上で求めた
をそのまま使えば良いので、
となります。
を使ってコスト関数の隠れ層の出力に対する微分を計算すると
となります。さらに合成関数の微分を進めていって交差エントロピー関数のxについての微分を計算していきます。
これで必要な計算はできたので、逆伝播についても実装してみます。先ほどのforward_prop()とまとめて一つの関数にします。
def forward_backward_prop(data, labels, params, dimensions): ofs = 0 Dx, H, Dy = (dimensions[0], dimensions[1], dimensions[2]) ### forward propagation W1 = np.reshape(params[ofs:ofs+ Dx * H], (Dx, H)) ofs += Dx * H b1 = np.reshape(params[ofs:ofs + H], (1, H)) ofs += H W2 = np.reshape(params[ofs:ofs + H * Dy], (H, Dy)) ofs += H * Dy b2 = np.reshape(params[ofs:ofs + Dy], (1, Dy)) h = sigmoid(np.dot(data, W1) + b1) y_hat = softmax(np.dot(h, W2) + b2) ### backward propagation delta = y_hat - labels gradW2 = h.T.dot(delta) gradb2 = np.sum(delta, axis = 0) delta = delta.dot(W2.T) * sigmoid_grad(h) gradW1 = data.T.dot(delta) gradb1 = np.sum(delta, axis = 0) ### cost_function cross_extropy_loss = -1 * np.sum(labels * np.log(y_hat)) cost = cross_extropy_loss ### Stack gradients grad = np.concatenate((gradW1.flatten(), gradb1.flatten(), gradW2.flatten(), gradb2.flatten())) return cost, grad
一応これで基本のニューラルネットワークの実装ができました!
gradient checkingで実装が間違っていないか確かめる
今回については手計算でできる勾配計算が多いのですが、それでもだんだん量が増えてきて
ちょっと本当に実装があっているのか不安になってきますよね…
そういう時はちゃんとgradient checkingをして
勾配計算の実装にミスがないかどうか確かめるのが大事です。
gradient checkingとはある番目に着目して以下の近似式で勾配を求め、その結果とbackpropで求めた勾配がだいたい一致するかを
確かめる作業です。
これが大幅にbackpropの結果とずれてたら、『あっ…(察し)』とどこかで実装がずれていることがわかるので、特に大規模なネットワークを自分で全部書くときは役に立つのかもしれない。
実際にこれを実装してみます。
def gradcheck_naive(f, x): rndstate = random.getstate() random.setstate(rndstate) fx, grad = f(x) # Evaluate function value at original point h = 1e-4 # xの全ての次元についてgradient checkingを行う it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) count = 0 while not it.finished: count+=1 ix = it.multi_index # 近似により勾配を求める。 x[ix] += h random.setstate(rndstate) fx_plus_h,_ = f(x) random.setstate(rndstate) x[ix] -= 2*h fx_minus_h,_ = f(x) x[ix] += h numgrad = (fx_plus_h - fx_minus_h) / (2*h) # backpropの計算結果と近似した結果の差異を比較する。 reldiff = abs(numgrad - grad[ix]) / max(1, abs(numgrad), abs(grad[ix])) print reldiff if reldiff > 1e-5: print "Gradient check failed." return it.iternext() # つぎのdimentionへ print "Gradient check passed!"
これで先ほどのforward_backward_prop()に適当なデータを入れて計算がちゃんとできているか確かめてみます。
def sanity_check(): N = 20 dimensions = [10, 5, 10] data = np.random.randn(N, dimensions[0]) labels = np.zeros((N, dimensions[2])) for i in xrange(N): labels[i, random.randint(0,dimensions[2]-1)] = 1 params = np.random.randn((dimensions[0] + 1) * dimensions[1] + ( dimensions[1] + 1) * dimensions[2], ) print params.shape gradcheck_naive(lambda params: forward_backward_prop(data, labels, params, dimensions), params)
実行してみると、
9.49366951697e-11 2.59475394025e-10 ... 4.01561339736e-10 5.21833463139e-11 7.50241228166e-11 Gradient check passed!
とほぼ差がないことがわかります。基本のニューラルネットの実装については大丈夫そうですね (◍ ´꒳` ◍)b
とりあえず今回までで基本のニューラルネットの勾配計算だったりをして実装してみるところまでできました。
次回(三が日までにはかけるように頑張ります…)は実際に今回実装したものをベースに、skip-gramやnegative samplingを実装して
実際に日本語wikipedia記事で単語ベクトルを作成してみたいと思います。
Women Techmakers Scholarship 2017に応募とその後!
このブログは情報系を勉強する女子大生 Advent Calendar 2017 - Qiitaの23日目の記事です。
今回は私がScholarships+ – Build your future with Googleという、Googleによる情報系を専攻する女子学生向けのScholarshipプログラムに応募した時の話、 また選出された後のどう行った活動をしているかについて紹介してみたいと思います。
Women Techmakers Scholarshipとは
Woman Techmakers Scholarshipとは、Googleによる情報系もしくは関連する分野を専攻する情報系の女子学生向けの奨学金制度であり、 APEC, North America, Europe/Africa/Middle Eastの三つのリージョンごとに奨学生を選出し、奨学金の支給やアウトリーチ活動(後述)への支援を行うものです。
私は昨年日本から選出された奨学生の方と元々知り合いだったこと、昨年Google検索チームでインターンした時のメンターがこのプログラムに少し関わっていて応募を勧められたこともあり、WTM APEC 2017に応募し、無事選出されました。
実際にScholar向けのretreatプログラムに参加してみたり日本に戻ってきた後日本から選出された他の奨学生と関わる中で色々刺激を受けたので、
もし今情報系に関連する分野(関連するの定義が難しいですが、必ずしも〜情報だけでなく数学、物理専攻寄りの方もいました)を専攻するなら応募してみるといいと思います!
りらちゃんが少し前のアドベントカレンダーの記事でプログラムの概要やretreat当日の詳細を書いてくれているので、興味のある方はこちらも見てみてください!
Women Techmakers Scholarshipの選考プロセス
昨年までは面接も選考のプロセスに含まれていたのですが、今年は書類選考のみでした。
Application Requirementsとして公式に掲載されているものは以下のようになります。これを全て提出すると応募が完了し、だいたい2ヵ月後くらいに選出されたか否かの連絡を受けます。
- General background information (includes contact information and information about your current and intended institutions)
- Current resumeAcademic transcripts from your current and prior institutions (if you have earned a prior degree)Responses to four essay questions(英文の成績証明書)
- Current resume (英文の履歴書)
- Responses to four essay questions(DiversityやOutreach Activitiesについての質問に200~500語程度で回答する)
General background informationはGoogle Formに自分の国籍だったりを入力する程度で、またCurrent resumeAcademic transcriptsについては東大の工学部の場合は英文の成績証明書が即日発行できるので、特に問題なく準備できました。
個人的にちょっと面倒だったのがCurrent ResumeとResponses to four essay questionsで、問題のなさそうな範囲でどんなことをしたのかを書いていこうと思います。
Resume(英文履歴書)の作成
応募にあたっては英文履歴書を用意する必要があります。また、Google STEPなどのプログラムでも英文履歴書での応募が推奨されています。 少し日本の履歴書と書き方やフォーマットが違ったりするので、「English Resume Software Engineer Intern」などで検索をかけると情報系の学部生の書くresumeがだいたいどう言った内容を含んでいるのかちょっこと見ることができると思います。
ただ正直日本からの応募者は例年そんなに多くないので、あまり気負わずにとりあえず書いて応募すればいいと思います!
とりあえず書いてみる
自分がresumeを作成するときは情報系の強いアメリカの大学の出しているresumeの書き方資料みたいなものを参考にしていました。
またresumeを作成するにあたって昔はWordやGoogle Docで作成していたのですが、「できるだけ見やすい」けど「デザイン的にもちょっとおしゃれ」かつ「プロっぽく見える()」をうまく両立しようと色々試行錯誤した結果、最近はもっぱらLaTexで作成しています。
また、resumeを書くときはオンラインでコンパイルができて共同編集も可能なOverleafを使用しています。(知り合いに添削してもらうこともあるため、これについても後述します)
Overleafについては様々なresume, CV(ちょっと長めの履歴書みたいなもの)が公開されているため、おしゃれで見やすいフォーマットを見つけてそれをベースにすると簡単に綺麗なresumeが作れます!
ちなみに自分の最近のお気に入りのフォーマットはDeedy CV - Overleaf, Online LaTeX Editorというフォーマットです。
添削してもらう
いったんresumeが作成できたら、できれば英語ネィティブ(かつソフトウェアエンジニアや情報系リサーチャーなどだとなお良い)の知り合いに添削してもらうと良いと思います。
私は昔このタイプの別のプログラムでとりあえず書いたまま提出したら書類で落とされた苦い経験があったので、今回は昨年のインターンの時のメンターに大体の添削をしてもらった後、アメリカの大学を卒業してソフトウェアエンジニアをしている友達、何度か進路の相談にのってくれたリサーチエンジニアの方に添削をお願いしました。
3人ともコンピュータサイエンス界のDiversityなどについて問題意識を抱えていてタイプだったので、もう一つのエッセイの方も色々コメントをくれてとても勉強になりました。
個人的にとても参考になったのが昨年のメンターからのコメントで、以下に引用しておきます。
I think for this scholarship you should expand your resume a bit, and include more details in the following sections:
Leadership, Awards, Research, Education
Since it is a scholarship program, leadership and prior awards will probably be the best topics to expand on for the program. I also think that you should expand 2-3 bullet dots for these leadership programs.
Leadershipというのは、例えば「女子中高生向けのプログラミング講座のメンターをした」「女性エンジニアと話す座談会を開催した」など、
今回の「情報科学分野における男女格差を是正する」ことを目的とするような活動や、もしサークルなどに所属していればそれを書けばいいと思います。
私は当時東大の女子学生向けのハッカソンの運営チーム兼学生メンターをしていたこと等を書きました。
こう言った目的に関連しなくても、例えばサークルの代表をしていた等、ボランティアをした等もリーダーシップ活動に含めればいいと思います。
Awardsについては過去の受賞歴(ハッカソン, プログラミング大会, 学会での受賞etc...)などを書ければ良いと思います。retreatで話したこの中にはICPCの参加経験のある子やプロダクトアイディアの世界大会に出ていた子もいました。
resumeは宗教があるみたいですがCVと違って基本的には1ページに収めることがよしとされるため、インターンのために作成したresumeをそのまま使い回すのではなく、
1ページから出ない範囲でscholarshipの応募では何を自分が伝えるべきかを考える必要がちょっとあるかもしれません。
自分の場合インターンの応募時にだす履歴書は Deedy CV - Overleaf, Online LaTeX Editorのフォーマットをそのまま使用してCourseWorksやSkillsなどもできるだけ明確に書くようにしているのですが、 WTMについてはこれらの項目をごっそり飛ばしてDouble ColumnをSingle Columnにして 「Education, Leadership, Experience, Awards」の4点に絞った構成にしました。
Responses to four essay questionsの作成
essay questionsについては年ごとに多少変動すると思うのですが、基本的には「なぜ自分がこの奨学金に応募したいと思ったのか」「これまで女性であることで不利な状況になったと感じたことがあるか」「仮にリサースがあればどのようなアウトリーチ活動*1をしたいか」などが聞かれると思います。
自分はこれについてもざっと書いた後に人に添削してもらって曖昧な点をもっと具体的にしたり、表現をより適切なものに変えたりしました。
こう書くとなんか大変そうですが、ぶっちゃけ他の国と比べて日本からの応募者は少なくて倍率低めだと思うのであまり気負わずに普段ちょっと嫌だなと感じたこと、
こうすればいいのになと思うことをつらつら書くといいと思います!
こんな感じで応募してまだかなまだかなって思いながら結果を待っていると今年は7月頃に「Scholarに選んだよ!」ってメールが届きました。わーい。

WTMのその後の話
WTMのretreatなどの詳細は Google Women Techmakers Scholarshipってなあに? - りらのひとりごとをぜひ読んでみてください!自分はWTM終了後に行なったことやその後のScholarたちとの交流について書いていこうと思います。
アウトリーチ活動について
WTMのScholarはその後「情報科学分野におけるDiversityの改善に貢献するような活動」(以下、アウトリーチ活動と呼びます)をGoogleの支援を受けて行うことも期待されています。
自分は年内はあまり多くの時間を取れなかったので、引き続き東大女子ハッカソンの運営や来年の準備を行なったり、
同じく東大からのScholarのKaviさんが主催した女子向け競技プログラミング勉強会でスタッフをしたり、Qiitaの情報科学を勉強する女子大生アドベントカレンダーを開始したりしています。

正直なところ、アウトリーチ活動に積極的に参加することについて「そんなことに時間を使う前にまずエンジニアとしてのスキルを磨くべきではないか」「エンジニアとしての自信がないからそういう活動に逃げているのではないか」と自問自答していた時期もありました。
でもやっぱりこういうイベントに関わったり主催してみて「プログラミングが楽しいと思った!」「もっと勉強してみたいと思った!」「普段男性ばかりで寂しかったから女の子のエンジニアとたくさん会えて楽しかった!」という声を聞くと、少しでも情報科学に興味があるけど躊躇ってしまっているような女の子の背中を押せたかなとうれしく思います。
りらちゃんの記事にもありましたが、「まだ未熟な自分がロールモデルなんて、前に立つなんて」と日和らずに、「私がロールモデルにならなきゃ、誰かを励ませるような存在にならなきゃ」って思うことも大切だなあと思っています。
他のScholarとのその後の関わりについて
WTM Scholarshipの特長として、情報科学を勉強する女子学生を支援するだけでなく、コミュニティ、ネットワークを作ることも主要な目的と据えていることです。そのため過去のScholarやプログラムに関わっているGoogleのエンジニア等の数百人規模のSlackやFacebookグループがあり、そこで様々な交流ができます。
Community
An online network with fellow scholars program participants designed to share resources, support the global community of women in tech and collaborate on projects to make continued impact.
また同じ年のScholarとは割とretreatで仲良くなれるので、その後も相手が日本に旅行に来た時にあったり、自分が相手の国行く時にあったりと行った交流も盛んです。
自分はretreatの時のルームメイトがシンガポール人の子で、「シンガポールに来るときは私が最高の旅行プラン立ててあげるから絶対教えてね!」と言われています笑。
また日本から選出されたScholar同士はやはり場所が近いので普段から「どんなアウトリーチ活動をすべきか」のミーティングをしたり、忘年会を開催したりと交流が盛んです。
自分があまり男性の方が圧倒的に多数派という環境に学科に入るまで体験したことがなかったため、
ごくたまにストレスを感じてしまうこともあり、そういう時にScholarの修士の先輩とスタバで悩みを聞いてもらったりもしました。
こんな感じでScholarとして選ばれた後もとってもいい友情だったりいいメンターだったりを見つけられるので、本当にWTMはおすすめです!! 来年の応募はまだ始まっていないと思うのですが、今年と同じであれば3, 4月くらいから始まると思うので、気になる方はぜひ応募してみてください :)
大学の実験でChromiumに勝手に機能を追加してみた話
これは Chromium Browserアドベントカレンダーの15日目の記事です。
この記事では所属する電子情報工学科の実験でChromiumに「指定したキーワードを含む特定の検索履歴のみ非表示にする」という機能を勝手に実装した時の体験をつらつら書いて行きたいと思います。
学科の先輩で現在Blink-Workerチームにいらっしゃるamiq11さんが在学中にこの実験のTAをされていたこともあって声をかけていただきました。
プロの方々によるとても素敵な記事ばかりが並ぶ中で恐縮ですが、「ちょっと勉強がてらChromiumのソースコードをとりあえず読んでみて、何かちょっとした機能を加えてみたい、改造したい」な
ニッチな人々の参考になれば嬉しいです…!
なんで大学の実験でChromium?
東大工学部電気系3年生は3〜6個のテーマの実験を行うことが必修となっており、私は今学期、他の二つの実験と併せて田浦健二郎先生による「大規模ソフトウェアを手探る」実験を履修しました。
この実験は「演習レベルの小さなプログラムが作れること」と、「実用規模のプログラムが作れること」のギャップを埋める (ための知識と経験を得る)ことを目的に、1〜数百万行のオープンソースソフトウェアをソースからビルドし新しい機能を加えたりします。
Chromiumの他にFirefoxのJavaScriptエンジン、SpiderMonkeyや最近そのリッチな自動補完などで人気なfish shellを題材にした班もあり、
実際に本家にPRを出して変更がマージされたりしています。
実験で追加した機能
今回私の班が実装したのは、「Chromiumの設定画面で非表示キーワードを設定すると、Chromium上部の検索ボックスの自動補完候補からそのキーワードを含む過去の検索履歴を除く」というものです。
Chrome上部の検索ボックスの正式名称は「Omnibox」といい、ユーザーの入力に従って、「過去に検索した検索クエリ」「過去に閲覧したページのURL」「Google検索で人気の検索」など様々なタイプの自動補完候補をサジェストしてくれています。
ちなみにsafariだとこんな感じ。Chromeでは様々なタイプの自動補完候補が並べられて表示されるのに対し、
safariはそれぞれの自動補完候補のタイプ別にセクションを分けているのがわかりますね。
今回はどう初心者がChromiumのソースからビルドして数百万行あるChromiumソースコードから変更したい箇所を見つけ、
機能を追加していくのかを書きたいと思います。
この実験では、実験レポートの代わりにブログ記事を提出可能というルールがあるため、
もしより詳細な内容(というか悪戦苦闘の様子)が知りたい奇特な方がいらっしゃれば下にそれぞれのステップと対応する、提出した記事の一覧を貼ったのでのぞいてみてください(゚▽゚*)
| 変更した内容 | ブログ記事 |
|---|---|
| ビルドする | 大規模ソフトウェア(Chromium)を手探る 導入・ビルド編 - あさりさんの作業ログ |
| ソースコードとドキュメントを手探る | 大規模ソフトウェアを手探る Chromeのソースコードとドキュメントをひたすら漁る - あさりさんの作業ログ |
| 検索ボックスのデータの流れを追い、自動補完候補にキーワードフィルターをかける | 大規模ソフトウェアを手探る 検索ボックスにおける自動補完・サジェスチョンのデータの流れを追う - あさりさんの作業ログ |
| user profileに新しい設定項目を追加 | 大規模ソフトウェア(Chromium)を手探る user profileに設定を追加する - あさりさんの作業ログ |
| 設定画面に非表示キーワードを新しく追加するための新たなWebUIをつける | 大規模ソフトウェア(Chromium)を手探る - 設定画面(settings)を手探る1 - - elechoのぶろぐ |
| 入力した情報をuser profileに引き渡すためのcall backハンドラを実装する | 大規模ソフトウェア(Chromium)を手探る callbackハンドラを追加する・全体の感想 - あさりさんの作業ログ |
ソースコードを(文字通り)手探る
実装する方法として、当初は以下の二つのアイディアを考えました。
- 入力に従って検索ボックスの自動補完情報を更新しているモジュール上で、特定の単語が含まれる検索履歴は自動補完候補から弾くようにする。
- 特定の単語が含まれる検索ワードはそもそも検索履歴DBに保存されないようにする。
そもそもデータにすら残さないのってどうなんだ?ということで、方針1で実装進めて行くことにしました。
Design Docを探してみる
Chromium Browser初日の記事で紹介いただいているように、
Chromiumには強力なコードサーチページがあります。ただ土地勘のない初心者が数百万行以上とも言われるChromiumのソースコードをいきなりそれっぽいキーワードでサーチする/目grepしようとすると、
果てしない壁にぶつかります。
もし趣味で手探ってみたい!という方がいれば、まず関連するDesign Docsを検索し、自分がいじってみたいモジュールはどれか、ソースコードはどのディレクトリにありそうか、ある程度目処をつけることをオススメします(自分の教訓です)。
Chromium (Chrome Browser, Chrome OS)の開発者向けドキュメント (design doc) は公式ホームページ、The Chromium ProjectのFor Developers>Design Documentsから検索できます。
ここでOmniboxで検索をかけてみると、Omnibox: History Provider - The Chromium Projectsというドキュメントに以下のような記述があるのを確認できます。
One of the autocomplete providers for the omnibox (the HistoryQuickProvider, HQP for short) serves up autocomplete candidates from the profile's history database. As the user starts typing into the omnibox, the HQP performs a search in its index of significant historical visits for the term or terms which have been typed.
HistoryProvider自体は過去の検索履歴から入力文字列とマッチしてそうなエントリを返すので、今回の「ユーザーの過去に入力した検索文字列」をOmniboxに供給している訳ではないのですが、 上の記述から自動補完候補は様々な種類のプロバイダからユーザーの検索履歴DBから供給されていること、ユーザーの入力に応じて入力文字列とマッチした過去の履歴を補完候補としてサジェストしているのが推測できます。
またChromeのUser Experiment関連のドキュメント、Omnibox - The Chromium Projectsをみると、いわゆる「ユーザーが検索の際に実際に入力した文字列に基づくサジェスチョン」はSearch Suggestというタイプに分類されているとわかります。 SearchProviderみたいな名前がついてそう………ざっくりですがだいたい目処がついてきました。
実際にコードをちょっといじってみる
Chrome Code SearchでSearchProviderクラスがどこにあるかちょっと調べてみると、 src/components/omnibox/browser/search_provider.cc で実際にSearchProviderクラスが実際に定義されていることがわかります。
最初は単純にこのSearchProviderの中でキーワードフィルターをかければいいのでは??と安易に考え、とりあえずある文字列とサジェスチョンが一致する場合は自動補完候補から除き、実際にサジェスチョンから消えるか確認してみることにしました。
SearchProvider::ScoreHistoryResultsHelper(...) {
SearchSuggestionParser::SuggestResults scored_results;
if (base::EqualsASCII(history_suggestions.suggestion(), “hogehoge”) == false){
scored_results.insert(insertion_position, history_suggestion);
}
return scored_result;
}
結果 : 普通に自動補完に出てきたwwwwww
どうやら単純にProvider側でとりあえず弾く、という実装だけでは不十分だったようなので、 ちゃんと自動補完のデータがどう流れてきているのか、デバッカで追ってみることにしました。
自動補完のデータの流れを追ってみる
地道にデバックやエラーのバックトレース結果をみると、Omniboxの自動補完候補は
- まず下図の右手側にあるそれぞれのProviderが入力とマッチするデータをprofileなどからそれぞれ取ってくる
- Controllerクラスがこれらすべての自動補完候補をAutocomoleteMatchesにまとめる(この結果が図のmatches_)
- 関連度等に基づいてこの自動補完候補をソートする(この結果が図のautcocomplete_result_)
- ソートされた結果が新たな自動補完候補として更新される
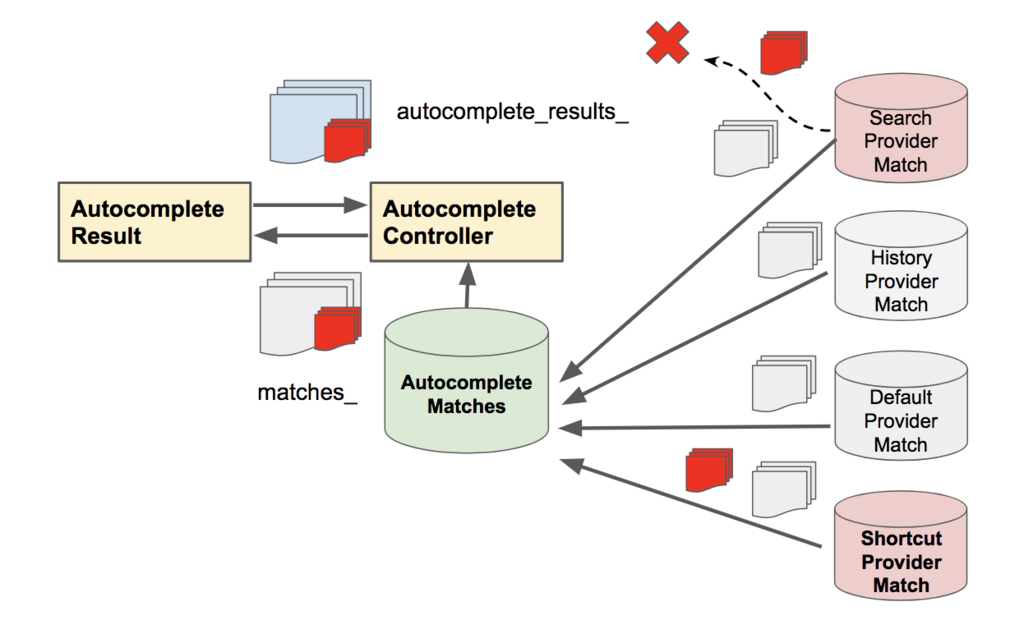
の流れで提供されていることがわかりました。
次に、一個一個プロバイダから自動補完データを渡している部分をコメントアウトする頭の悪い感じの作業をしてSearchProviderの候補から確かに除いたはずの
非表示キーワード自動補完がどこから流れてきたのか検証してみると、実はShortcutProviderというクラスから弾いたはずのデータが供給されていることがわかりました。
Providerの中でも一番下に示された意味ありげなShortcutProviderというProviderクラス、当初はあまりちゃんとマークしていなかったのですが、 このクラスのヘッダーファイルを見てみると以下の記述があります。
// Provider of recently autocompleted links. Provides autocomplete suggestions // from previously selected suggestions. The more often a user selects a // suggestion for a given search term the higher will be that suggestion's // ranking for future uses of that search term. class ShortcutsProvider : public AutocompleteProvider, public ShortcutsBackend::ShortcutsBackendObserver {...}
"Provider of recently autocompleted links. Provides autocomplete suggestions from previously selected suggestions. "
ん??????
つまりこれをみると、最近サジェストされ、ユーザーが実際に検索した候補のデータを別のDBに保存し、そこからデータを供給していることがわかりました。 こうすると例えSearchProvider側であるキーワードを含むものを自動補完候補から除いても、こちらのProvider側が読み込んでいるDBにすでに 非表示キーワードを含んだ履歴が残されていると、こちらからデータが供給されてしまうことがわかります。

それぞれの個々のProviderにフィルターをかけるような実装でもよかったのかもしれませんが、自動補完として集められた結果に割と重複が多いことからも無駄が多いのではないか?という指摘をTAの方にいただいきました。
そこで以下のように、全ての補完候補をまとめて重複を除いた後、非表示キーワードを含むないしは非表示キーワードと一致する自動補完結果については除外するように変更を加えました。
後述するUser Profileの情報を読み込んで非表示キーワードが設定されていた場合にはSortAndCullWithKeyword()関数を呼び、このSortAndCullWithKeyword()は非表示キーワードを含むかどうかfind()で判定し、のぞいた後に
SortAndCull()という候補のソートを行う関数に渡しています。
bool IsRemovableTypeFromMatch(AutocompleteMatchType::Type type) { return type == AutocompleteMatchType::HISTORY_TITLE || type == AutocompleteMatchType::HISTORY_BODY || type == AutocompleteMatchType::SEARCH_HISTORY || type == AutocompleteMatchType::SEARCH_SUGGEST_TAIL; } } // namespace void AutocompleteResult::SortAndCullWithKeyword( const AutocompleteInput& input, TemplateURLService* template_url_service, const std::string& keyword) { std::vector<base::string16> restricted_keywords = TokenizesKeywordsStringToKeywordsVec(keyword); const base::string16& input_text = input.text(); matches_.erase( std::remove_if( matches_.begin(), matches_.end(), [&restricted_keywords, &input_text](const AutocompleteMatch& match) { bool removable = IsRemovableTypeFromMatch(match.type); if (removable) { base::string16 match_text = base::ToLowerASCII(match.contents); for (auto& restricted_keyword : restricted_keywords) { // Omniboxの入力文字列と一致しないかつ表示したくないキーワードを含む検索候補を除くように書き換える。 if (input_text != match_text && match_text.find(restricted_keyword) != base::string16::npos) { return true; } } } return false; }), matches_.end()); SortAndCull(input, template_url_service); }
IsRemovableTypeFromMatch()は自動補完候補がユーザーの過去の検索に基づくものであるかどうか判定し、過去の検索クエリや訪問履歴に基づいた自動補完データ出会った場合のみ、
非表示キーワードを含む自動補完候補を候補から除きます。
これは「自動補完候補のうち、キーワードを含むものは全て除く」とすると普段の検索でGoogle検索で人気のキーワードに基づく自動補完候補なども消去されてしまうために、普段の利用で不便が生じそうと考えたためです。
余談ですが、kRestrictedKeywordについてはカンマ区切りにすれば複数キーワードも指定可にしており、TokenizesKeywordsStringToKeywordsVec(keyword)でtokenizeをしています。
User Profileに非表示キーワードを追加する
上の変更で指定されたキーワードを含む自動補完候補フィルタリングについては機能するようになりました。あとは非表示したいキーワードをChromeの通用の設定画面で追加できるようにしたあと、 User Profileに保存してC++側から参照できるように変更を加えます。
Preferenceに非表示キーワードを追加する
ユーザーの登録したChromiumの設定はUser Profileのpreferenceに保存され、それぞれに固有のkey(pref_name)によって識別されます。 preferecesに任意の設定について追加したい場合には、
- PrefNamesクラスで新しく設定したいpreferenceのnameとデフォルト値を登録する。
- ProfileImplクラスのRegisterProfilePrefsd()という関数でこのpreferenceを登録する。
というステップでProfileにこの新しいpreferenceの値がストアされるようになり、PrefServiceを呼ぶことで、C++のプログラムから参照できるようになります。
preferenceへの新たな項目の追加はchrome/common/pref_names.h及びchrome/common/pref_names.cppに以下のように追加します。
まずkRestrictedKeywordをchrome/common/pref_names.hで宣言します。
namespace prefs { // Profile prefs. Please add Local State prefs below instead. ... extern const char kRestrictedKeyword[]; } // namespace prefs
次に、cpp側でUI(JavaScript)側からこのpreferenceを参照する時に必要なpref_nameを登録します。ここに格納される値はデフォルト値ではなくてキーとして使われる識別子です。
namespace prefs { // *************** PROFILE PREFS *************** // These are attached to the user profile ... const char kRestrictedKeyword[] = "RestrictedKeyword"; } // namespace prefs
最後にProfileImplクラスのRegisterProfilePrefsd()という関数でこのpreferenceを登録します。ちなみにこれをやらないと実行時にコアダンプします。
// RegisterProfilePrefsd()というvoid関数でpreferenceの登録が行われている void ProfileImpl::RegisterProfilePrefs( user_prefs::PrefRegistrySyncable* registry) { registry->RegisterBooleanPref(prefs::kSavingBrowserHistoryDisabled, false); ... registry->RegisterStringPref(prefs::kRestrictedKeyword, std::string()); }
AutocompleteController側からPrefServiceを呼び出す
ユーザーのpreferencesを取得するためには、PrefServiceをservice clientから呼ぶ必要があります。
自動補完候補のソートを行なっているAutocompleteResultクラスは、service clientに順ずるものに直接はアクセスできないため、AutocompleteController側でkRestrictedKeywordを取得し、SortAndCullWithKeyword()関数に渡す形で実装することにしました。
void AutocompleteController::UpdateResult( bool regenerate_result, bool force_notify_default_match_changed) { PrefService* prefs = provider_client_->GetPrefs(); const std::string keyword = prefs->GetString(prefs::kRestrictedKeyword); // 非表示キーワードが設定されていた時はSortAndCullWithKeyword()を、 // そうでない時は通常のSortAndCull()を呼ぶ。 if (keyword) { result_.SortAndCullWithKeyword(input_, template_url_service_, keyword); } else { result_.SortAndCull(input_, template_url_service_); } ... }
設定画面に非表示キーワード登録欄を追加する
ここまでの変更でpreferenceの情報を取得し、登録された任意の一つもしくは複数のキーワードを含む自動補完候補のフィルタリンリング機能の実装が完了しました。
あとは実際にChromeのデフォルトの設定画面に非表示キーワードを登録できるようにUIを変更すれば完成です。
WebUIを変更する
まず設定画面のHTML, JavaScriptファイルを追加ないし変更をして、非表示キーワードを登録するセクションを追加します。
WebUIの変更については同じチームのelechoくんが以下の記事で詳細にまとめていくれているので興味がある方はelechoくんの記事も呼んでください :)
elecho.hatenablog.com elecho.hatenablog.com
ChromeのWebUIの変更については以下のドキュメントが参考になりました。
ドキュメントにもあるように、WebUIの変更にはWebUIページの作成だけでなく、リソースへの追加、ルーティングの設定等、多くのファイルの変更が必要となり、
どこか忘れると正しく表示されなかったりして、またデバックもいい方法がわからず苦労しました…
ChromeでのいいWebUIのデバッグ方法が知りたいなとちょっと思いました。
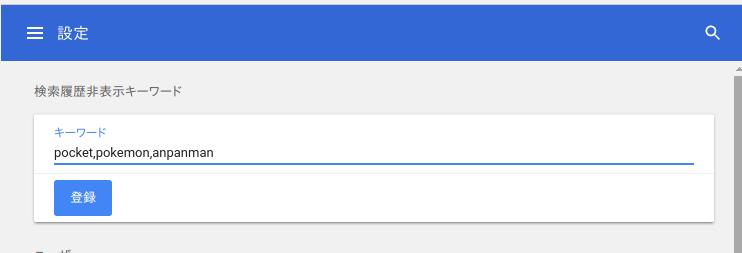
実際にChrome Settingsにキーワード登録セクションを追加しました。(画像は授業内でのデモ用に設定画面の一番上に非表示キーワード登録セクションを追加してみます)
callbackハンドラを追加する
ドキュメントにも紹介されていますが、新たに追加したWebUIからC++モジュールの情報を参照したり、JavaScript側でのsettingsでの変更をC++のPrefServiceを用いてuser profileに追加するためには、 メッセージコールバックハンドラを追加する方法が推奨されている(みたいです)。
You probably want your new WebUI page to be able to do something or get information from the C++ world. For this, we use message callback handlers. Let's say that we don't trust the Javascript engine to be able to add two integers together (since we know that it uses floating point values internally). We could add a callback handler to perform integer arithmetic for us.
ここについては特に手探りで行なった部分も多く、誤りなどあるかもしれませんが、以下のような手順でcallbackハンドラクラスを追加しました。
- handlerクラス(h, cppファイル)を追加する。
- MessageCallbackを登録し、JavaScriptで呼ばれる関数名と対応するC++プログラムでの関数名を決める
- 実際に呼ばれるC++の関数の動作を定義する
- 追加したハンドラを新しくビルドターゲットに追加する
handlerクラスを追加する
新しくmessage callback handlerを追加する場合にはchrome/browser/ui/webui/settings/以下にsettings_restricted_keyword_pages_handler.h
とsettings_restricted_keyword_pages_handler.cppファイルを加え、設定画面の別のセクションのcallback handlerを参考に実装しました。
RestrictedKeywordHandlerクラスのヘッダファイルはこんな感じ。
class RestrictedKeywordHandler : public SettingsPageUIHandler, public ui::TableModelObserver { public: explicit RestrictedKeywordHandler(content::WebUI* webui); ~RestrictedKeywordHandler() override; // SettingsPageUIHandler: void RegisterMessages() override; void OnJavascriptAllowed() override; void OnJavascriptDisallowed() override; // ui::TableModelObserver: void OnModelChanged() override; void OnItemsChanged(int start, int length) override; void OnItemsAdded(int start, int length) override; void OnItemsRemoved(int start, int length) override; private: PrefChangeRegistrar pref_change_registrar_; CustomHomePagesTableModel restricted_custom_page_table_model_; DISALLOW_COPY_AND_ASSIGN(RestrictedKeywordHandler); };
MessageCallbackを登録する
callback handlerクラスで定義されたC++の関数をMessageCallbackに登録することで、JavaScriptから指定した関数名で呼べばregisterしたC++の関数が呼ばれるようになります。
今回はprefs::kRestrictedKeywordを追加する関数setRestrictedKeyword、またユーザーが設定画面を開いた時に今の設定値を見えるようにJavaScriptに情報を渡すための関数getRestrictedKeywordを追加します。
先ほど作成したsettings_restricted_keyword_pages_handler.cppのRestrictedKeywordHandler::RegisterMessages()で登録を行います。
void RestrictedKeywordHandler::RegisterMessages() { if (Profile::FromWebUI(web_ui())->IsOffTheRecord()) return; web_ui()->RegisterMessageCallback("setRestrictedKeyword", base::Bind(&RestrictedKeywordHandler::HandleSetRestrictedKeyword, base::Unretained(this))); web_ui()->RegisterMessageCallback("getRestrictedKeyword", base::Bind(&RestrictedKeywordHandler::HandleGetRestrictedKeyword, base::Unretained(this))); }
実際に実行されるC++関数を追加する
実際にuser profileを取得して登録されたキーワードの情報を取り出したり、設定画面でキーワードが登録された際にpreferenceを変更する関数をsettings_restricted_keyword_pages_handler.cppに実装していきます。HandleAddRestrictedKeyword()ではWebUIからProfileを取得し、JavaScript側から渡されたvalue(新しく追加されたキーワード)をprefs::kRestrictedKeywordにセットします。また、
C++側でpreferenceから現在のキーワードを取得し、JavaScriptにcallbackを返すためのHandleGetRestrictedKeyword()関数も追加します。
void RestrictedKeywordHandler::HandleAddRestrictedKeyword(const base::ListValue* args) { std::string pref_name; args->GetString(0, &pref_name); const base::Value* value; args->Get(1, &value); PrefService* prefs = Profile::FromWebUI(web_ui())->GetPrefs(); prefs->SetString(prefs::kRestrictedKeyword, value->GetString()); } void RestrictedKeywordHandler::HandleGetRestrictedKeyword(const base::ListValue* args) { CHECK_EQ(1U, args->GetSize()); const base::Value* callback_id; CHECK(args->Get(0, &callback_id)); AllowJavascript(); ResolveJavascriptCallback(*callback_id, base::Value(GetRestrictedKeyword())); } std::string RestrictedKeywordHandler::GetRestrictedKeyword() { std::string RestrictedKeyword; PrefService* prefs = Profile::FromWebUI(web_ui())->GetPrefs(); RestrictedKeyword = prefs->GetString(prefs::kRestrictedKeyword); return RestrictedKeyword; }
ビルドターゲットに追加する
新しくsourcesを追加する時はgnファイルに追加したファイルへのパスを登録をし、ビルドターゲットに追加します。
通常はchrome/browser/ui/BUILD.gnにccファイルとhファイルへのパスを追加するのみですが、
設定画面の変更については別にSettingPagesHandlerとしてchrome/browser/ui/webui/settings/md_settings_ui.ccに以下のように追加する必要がありました。
この辺りについては類似するクラスを参照しながら必要そうな変更にあたりをつけていきました。
#include "chrome/browser/ui/webui/settings/settings_restricted_keyword_pages_handler.h" MdSettingsUI::MdSettingsUI(content::WebUI* web_ui) : content::WebUIController(web_ui), WebContentsObserver(web_ui->GetWebContents()) { ... AddSettingsPageUIHandler(base::MakeUnique<RestrictedKeywordHandler>(web_ui)); ... }
まとめ
短い時間でしたが、Chromiumのソースコードをコードサーチやdesign docをフル活用して手探る中で、
ブラウザでのざまざまなプロセスの動きやC++世界とJavaScriptの世界でどうやりとりがなされているか、またChromiumでのWebUIの構成など
様々なことが学べました。
Chromiumに実際にコミットしなくても、「こんな機能できないかな…!!」くらいの気持ちで色々いじってみるととても勉強になるので
年末年始暇な方などは遊んでみてください〜 :)
Word2Vecモデルをスクラッチで実装してみる ① そもそもWord2Vecって?
この記事は情報系を勉強する女子大生 Advent Calendar 2017 - Qiitaの9日目の記事です。
実は春休みにインターンで自然言語処理のプロジェクトをやって以来この領域が好きで、
今回はそのきっかけになった単語ベクトルの話をしていこうと思います(・x・)
※B3が趣味で書いているだけなので曖昧な説明、「数学的にアレ」な部分が散見されると思うのですが見つけた場合は優しくコメントいただけるととっても嬉しいです...
ちなみにつらつら書くだけより実際に実装してみたほうが頭に入りそうだな〜ということで3つの記事に分けて
基本のモデルを追うところからPythonで実際に実装するところまでやるつもりです!
最初2回は情報系を勉強する女子大生 Advent Calendar 2017 - Qiitaに、最後1回は自分の所属する東大電気電子電子情報工学科のアドベントカレンダー、
eeic (東京大学工学部電気電子・電子情報工学科) Advent Calendar 2017 - Qiitaに載せるつもりなので、興味があればそちらもみてみてください〜
今回の記事を書くにあたってスタンフォード大学のCS224N:Deep Learning for NLPの授業を参考にしています。
授業スライド、参考資料、課題、講義ビデオ全てネット上で公開されているので、自然言語処理における深層学習に興味がある方はぜひ見てみてくださいヾ(@°▽°@)ノ
単語の意味をどう表現するか
自然言語はそのままでは深層学習や機械学習モデルに入力として入れることはできず、なんらかの形でコンピュータが理解できる形で単語の意味を教えていかなくてはいけません。
一番シンプルなのは単語ごとになんらかのカテゴリだったり特性(good, negative, positive...etc)のラベルを振っていくとかができそうです。
WordNet | A Lexical Database for Englishは英単語がsynsetと呼ばれる同義語のグループに分類され、簡単な定義や、他の同義語のグループとの関係が記述されています。
NLTKという自然言語処理でよく使われるPythonのライブラリでこのWordNetのためのインテーフェイスがあり、以下の感じで「panda」のhypernym(上位語)が取得できます。
from nltk.corpus import wordnet as wn
panda = wn.synset('panda.n.01')
hyper = lambda s:s.hypernyms()
list(panda.closure(hyper))
ちなみに結果はこんな感じ。
[Synset('procyonid.n.01'), Synset('carnivore.n.01'), Synset('placental.n.01'), Synset('mammal.n.01'), Synset('vertebrate.n.01'), Synset('chordate.n.01'), Synset('animal.n.01'), Synset('organism.n.01'), Synset('living_thing.n.01'), Synset('whole.n.02'), Synset('object.n.01'), Synset('physical_entity.n.01'), Synset('entity.n.01')]
procyonid(アライグマ科), carnivore(肉食動物), placental(有胎盤類), mammal(哺乳類), vertebrate(脊椎動物), chordate(脊索動物), animal(動物),
organism(生体)m living_thing(生き物), whole(全体), object(物体)...
うん、上位語は正しそう!が、こんな感じのラベリングとか概念定義を存在する全単語にやるのはちょっと現実的に厳しそうです……
また同義語に対して細かい意味の違いを表現できないのではないかという指摘もされています。さすがにこれじゃ厳しい、ということで次に出てきたのがOne hotな単語表現でした。
One hotによる局所的な表現
例えばあるデータセットにN単語含まれるならばN次元のベクトルを作り、そのベクトルの中でt番目だけ1を立て、残りは全て零とするOne hot表現が用いられていました。
例えばもし異なる10単語が登場する文章が与えられた時、文章中に登場するhotelとmotelという単語はそれぞれ以下のように表現されることになります。
このような表現は何が問題なのでしょう?まずこの表現だと、もし単語数が数百万、数千万…と増えていくと、巨大で疎ベクトルが必要になり、計算コストもメモリも心配になります。
また、これ内積をちょっと計算してみると
直交しており、類似度が全くないとなってしまうことがわかります。motel, hotelという類似語についてのベクトル表現のはずなのに、類似度の概念をOne hotベクトルでは全く捉えることができないために失われてしまいます。これもあまり望ましくないですよね…
分散的な単語表現とは
単語の意味をより密なベクトル表現を使って単語を表現できないか、という考えがここから出てきます。例えば、1万の単語をそのままOne hotベクトルで表すと1万次元が必要になるけど、
これを100~300くらいの密なベクトルにできれば、コストを減らすこともできそうだし、単語間の類似性ももうちょっとちゃんと捉えられそうです。
こういった単語のベクトル表現を「分散的な単語表現」と呼びます。ここで大事になってくるのが、
distributional hypothesis(意味的に近い単語は同じ文章に出現するはずだ)というもので、Word2Vec, Glove, fastText等の著名なモデルではこの考えを元にしています。
分散的な単語表現の基本的な考え方
基本的にはあるwordとその周辺のcontext words(もし"I love dogs and cats"という文章があり、"dogs"というwordに着目するならcontextは"I", "love", "and", "cats"ということになります)の間の条件付き確率を求め、これをコーパス中の全ての単語に対して行い、全体での目的関数を最大化するようパラメータを調節します。
....よくわからないですね !!!! ということで分散的な単語表現を行うモデルのうち、おそらく一番有名なWord2Vecというモデルに焦点を当てて何を具体的に計算しているのか、考えてみます。
Word2Vecとは
Word2Vecモデルとは上で書いたような「単語を密なベクトルでいい感じに表現する」モデルの代表的なものの一つであり、米グーグル(当時)の研究者であるトマス・ミコロフ氏により提案されました。
「queen - woman = king」の例を耳にしたことのある方も多いのではないでしょうか。
密なベクトル表現により文章に含まれる単語同士の類似度や、単語間での加算・減算などができるようになり、
またニューラルネットワークの入力の素性に利用できるようになったことで、ディープラーニングの自然言語処理への応用が
進んだとも言われています。
Word2Vecのメインの二つのアルゴリズムに、前後の単語からある単語を予測する「CBoW」と、ある単語から周辺の単語を予測する「Skip-gram」があり、この二つがあるのですが、CBoWについて書いている最中にスタバwifiが切断された結果書きかけの記事が吹き飛んで萎えたので今回はとりあえずSkip-gramにフォーカスを当てたいと思います。
Skip-gram
Skip-gramはCBoWの逆の方向で考え、単語(word)からその周辺単語(context)を予測します。
例えば{"I", "love", "playing", "tennis", "pizza", "eating", "am"}のような単語が与えられた時、"I love playing tennis", "I love pizza"は文章として自然ですが、
"I am pizza"や"I tennis"はちょっと気持ち悪いですよね。
これが私たちが無意識に「"pizza"という単語が与えらられた時にはおそらく周りには"like", "eating"などの動詞がくるの」「"I"という主格代名詞の直後にいきなり"tennis"や"pizza"などの普通名詞が
登場するのはおかしい」と、ある単語からその単語が使われそうな文脈を予測しているためです。
Skip Gramではこんな感じで、ある単語が与えられた時、
その周辺(context)にはどんな単語がくるべきかを条件付き確率で表します。
例えばbankingという単語を中心に考えてみます。
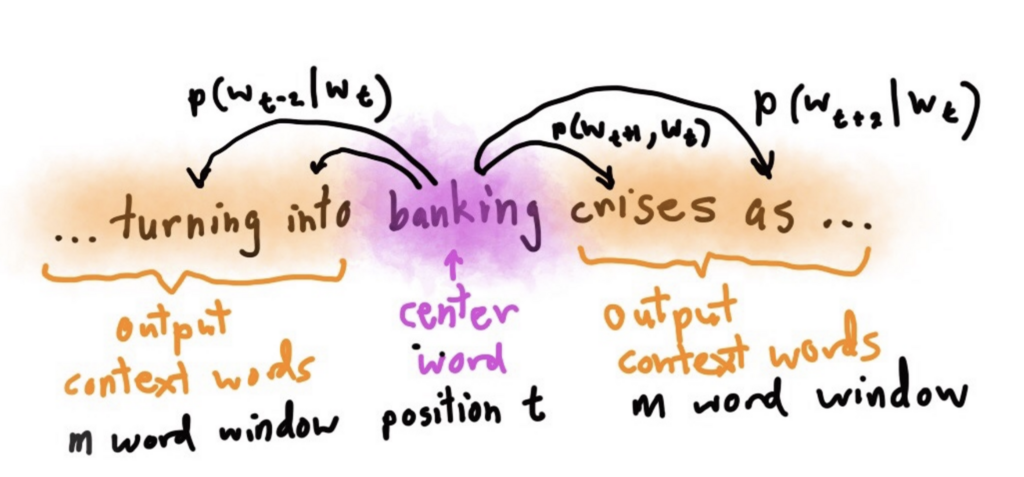
とすればある単語の前後100単語までは周辺単語と解釈することもできるのですが、実際私たちがある単語について考える時、ここまで離れた関係で考えたりはしないと思うので、windowサイズはそこまで大きく設定はされません。
上の例だとbankingとcrisisっていう単語は割と一緒に出てきそうなので、とかは確率として高くなるようになってほしいですね。
はおそらくありうるとは思うのですが、
よりは発生頻度が低くないなりそうなので、確率としてはやや低くなりそうです。
じゃあ実際にこの条件付き確率はどうやって計算し、また「こういう使い方はありえそう」というものをより高くするために、パラメータはどう調整するのでしょう。
Word2Vecでは次のようにソフトマックスでモデル化します。
は中心の単語
の周辺の単語を表ており、
は
の単語ベクトル、
は出力ベクトルを表ています。
はコーパス(学習に使う文章)に含まれる全ての単語を表ており、このように周辺単語
の出力ベクトル
と
の内積をとり、
それを正規化することで、
と
が共起する確率を求めます。
目的関数は、ある中心の単語を考えた時、実際にその周囲に出現した単語の条件付き確率の同時確率を最大化すれば良いので、以下のような目的関数を考えます。
このままだとちょっと計算しにくいので、対数尤度関数をとって、かつマイナスをかけて以下のような関数にします。
ここでは全ての最適化可能なパラメータを意味しています。
あとはパラメータをいい感じに最適化してこの関数を最小化するだけです! 実際にどう最適化するのかなどは次の記事で紹介しようと思います。今回はざっくりSkip-gramが何をしているのかが伝わればうれしいです :)
なんでこれ面白いと思ったの
※ここからは完全に個人的な私見です | _・)チラッ
自分の場合単語ベクトルの話が個人的に自然言語処理おもしろい!ってなった最初のきっかけの一つだったような気がします。
ある単語から周りにこんな単語がきそうだと予測する」(skip-gram)や「周辺の単語から中心の単語はこんな感じだろうと思う」(CBoW)の考え方って割と私たちが普段文章を読むときになんとなくやっている行動に近いなと思いました。
子供の頃小説を読んでいるときに特定の漢字が読めないときやTOEFLなどの英語の試験でわからない単語が出てきたとき、前後を読んで「多分この単語はこんな意味だろう」と予測を立てたり、文章を組み立てるときに「この単語と一緒に使われるべきはこれだな」って考えたりしませんか?
これを上のように数式できちんとモデル化して、しかも割と人間が見ても「あ、確かにその単語同士は似ているよね」「確かにその単語とその単語引くとそうなりそう!」みたいな関係性をきちんと捉えられるのってすごい面白いな〜(ふわ〜)と個人的には思っているので、今回記事を書いて見ました。
ざっくりと曖昧な説明でごめんなさいなのですが、少しでもへ〜って思っていただけたらうれしいです。
ハッカソンのススメ
このブログは 情報系を勉強する女子大生 Advent Calendar 2017 - Qiitaの一日目の記事です。
ハッカソンとは
情報系の勉強をしているならなんとなく「ハッカソン」という言葉だけは聞いたことがあるのではないでしょうか。簡単にいうと、「ある決まった短い時間でゼロからアイディア出し、プロダクトの実装を行いピッチ、デモを行い成果を競い合うイベント」です。
「旅行」「家庭」など、ゆるくお題を与えられているものもあれば、「モバイルアプリ」など技術やプラットフォームを制限したもの(SPA-JAM)、また面白ければなんでも好きなものを作っても良いというハッカソン(Yahoo HackDay)もあります。
1ヶ月など中長期の開発コンペとの比較して際立つのが、「アイディアをじっくりと議論をする時間は(基本的には)ない」「とにかく拙速でも機能を実装仕切ることが大切」「1 ~ 10分のごく短い時間ピッチでアイディアを伝え、実装したもののデモンストレーションをしなくてはいけない」等だと思います。こう書くとちょっと難しそうですが、一種のお祭り騒ぎみたいな感じですごく楽しいので、今回ハッカソンを布教するための記事を書くことにしました。
ハッカソンに出ると何がいいの?
「ハッカソン メリット」とかググると色々な記事がヒットすると思いますが、個人的にハッカソンを出て感じた 「まだ実務経験がそれほどあるわけではない大学生エンジニアが感じるハッカソンのメリット」をいくつかあげたいと思います。
限られた時間の中でチーム開発をする体験ができる
事前開発が可能なケースもありますが、基本的にハッカソンは1~2日の短い時間でゼロから実装をしなくてはいけない場合がほとんどです。
そのため、チームで「期限までにどのようなスケジュールで開発を進めるか」「実装はどう分担するか」「どの機能を優先して実装し、余裕があったら実装する機能はどれか」
を決めて開発を進めていきます。
また分担をしながら効率的に機能実装を進めるためには、Gitなどのツールをきちんと使いこなす必要があります。
普段の大学の課題を進めるだけでは、スケシュールを決められている中でのgitを用いたチーム開発を進めることはあまり多くはないと思うので、
こういったハッカソンなどに参加すると勉強になります。
また時間が限られているために、ライブラリ、API、訓練済みのモデルを上手く活用することも
大きな鍵になってきます。既存のツールのドキュメントやリファレンスをざっと読み、実際に活用できそうか考え、試して、
使えそうならプロダクトに組み入れるといったフローもハッカソンで経験できました。
自分のプロダクトを簡潔に伝える練習ができる
ハッカソンでは大抵最終日にハッカソン中に開発したプロダクトの数分間ピッチを行います。
大会にもよると思うのですが、私がこれまで出た大会では1分半~3分しかピッチ時間のないものがほとんどでした。
この時間ではゆっくりとシステム構成の説明している時間はもちろんなく、「解決したい問題は何か」
「この問題をどう解決しているのか」「実際に機能するのか(デモ)」などを簡潔に、しかし重要な点はしっかりと伝わるように話さなくてはいけません。
こういったピッチの経験は「何を、どうやって相手に伝えればわかってもらえるのか」を理解する上でとてもいい経験になりました。
また個人的には、繰り返し人前でピッチをすると少しだけ以前より場慣れするので、昔ほどプレゼンテーションに対して上がらなくなりました。
(今でもそこまで得意ではないのですが…)
企業の人、他大学のエンジニアの人と知り合うことができる
特に大学生限定のハッカソン(HackUやJPHacksなど)では、自分の専攻、大学だけでなく
他大の人と懇親会などで関わる機会があります。技術力のある人、面白いアイディアを持っていた人など、同年代の様々な人と知り合えるのでとても刺激になります。
またハッカソンは企業が協賛していることが多く、企業の方に自分のプロダクトを見てもらったり、懇親会で話を伺うことができ、
進路を考えたりする上でも参考になります。また企業賞などを受賞をするとその後もランチのお誘いであったり、インターンの声をかけていただりもするので結構おいしいと思います…!
とにかく楽しい!
と言いつつ、個人的にハッカソンのいいところって友達とアイディアから実装まで、1日で作っちゃうお祭り感かなと思います。 毎回ハッカソンに出るときはほぼ徹夜になってしまうことも多いのですが、コーヒー、レッドブルと一緒にやお菓子と食べながらたまに冗談を言いながら開発したりするのは毎回とても楽しいです。
わたしのハッカソン体験談
私もそこまでたくさん出ているわけではないのですが、JPHacks 2016, 2017の東京大会と本選、またHackDay 2016にほぼ同じメンバーで出場しました。最初は学科に入ってすぐの時期にSlackで「ハッカソン出たい人募集」といった投稿を学科の同級生(今のチームメイト)がして、それに反応した5人くらいでチームを組みました。
「ハッカソン一緒に出る友達がいない…」という声をたまに聞きますが、こんな感じで「とりあえず学科の人に声をかけてみる」「会場でぼっちの人とチームを組む」などもできると思うので、どんどん参加してみましょう( •̀ᄇ• ́)ﻭ✧
私は基本的に全てでクライアント(iOS)開発と、たまにちょっとデザインを触ったりしていました。 以下は過去のハッカソンで製作したものになります。
FreshFridge, Migaは二つとも全国規模の学生ハッカソンであるJPHacksの際に開発したものであり、
「家庭からの食品の廃棄を減らす」「夜道での女性を狙った犯罪を予防、被害を軽減する」など社会問題にフォーカスしたものになっています。
これは裏技(?)なのですが、「問題解決」を重視する大会では何らかの社会問題を重視したもの、「面白さ」を重視する大会ではネタに突っ走るなどある程度大会の趣旨とテーマを寄せると評価されやすいと思います。( •̀ᄇ• ́)ﻭ✧
FreshFridgeの時はほぼ初対面のメンバーで開発を始めたので最初は色々苦労したのですが、
色々なライブラリ、APIの活用やデバイスを用いたサービス開発をする中でとても多くの学びを得ることができました。ただgitの使い方で最初ミスをしまくったので事前にもっと勉強しておけばよかったなあと思います…
もしこれからハッカソンに参加しようと思っている人がいるなら本やサイトなどでチーム開発の仕方をマスターしておくとスムーズに開発できると思います。個人的には「GitHub実践入門」がわかりやすくておすすめです!
")
GitHub実践入門 ~Pull Requestによる開発の変革 (WEB+DB PRESS plus)
- 作者: 大塚弘記
- 出版社/メーカー: 技術評論社
- 発売日: 2014/03/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (23件) を見る
またMigaの時は逆にもう1年経ってよく知っているメンバーだけに、事前開発期間はあったのですがはあまり緊張感が持てず開発などはせず、
またテーマが迷走した結果、当日テーマ決めをしてようやく夕方から開発が開始できたので、とてもヒヤヒヤしました…
ちなみに前日時点でのテーマ決めはこんな感じでだいぶ迷走していました…

事前開発が可能な大会に出る時はちゃんと早めから準備をするといいと思います。
どちらも色々とトラブルはありましたが、結果的にFreshFridge, Migaとも全国大会に出場でき、いくつかのスポンサー賞やイノベーター認定をいただくことができました。

テーマッテッダイジ…………
ハッカソンの紹介
ハッカソンの情報については毎年まとめてくださっている方がいるので、「ハッカソン 2017」とかでググると割とまとまった情報がゲットできると思います。またSPA JAM、HackDay、JPHacksなどは毎年開催しているので、公式サイトをこまめにチェックするといいと思います!
女子向けハッカソンの紹介
と言いつつ、こういったハッカソンっていわゆる「ガチプロ」が多くて最初は敷居が高く感じてしまいますよね…
個人的には女子向け/初心者向けハッカソンにまず出場してみて、ハッカソンってどんなものか体験してみるといいと思います。
私は東大Girlsハッカソンという、東大女子限定のハッカソンの運営に今年関わっていました。 スポンサーの方やメンターの方からの手厚いサポート、Progateなどのオンライン学習サービスの無料利用権などもあり、まだ開発経験がそこまで多くないけどハッカソン出てみたい!もっとプログラミング勉強してみたい! という方には本当にオススメです!
大学以外にも、女性限定の開発コミュニティが主催する女性限定ハッカソン等もあるので、探してみるといいと思います!
さあとりあえずハッカソン出てみよう!