Word2Vecモデルをスクラッチで実装してみる ① そもそもWord2Vecって?
この記事は情報系を勉強する女子大生 Advent Calendar 2017 - Qiitaの9日目の記事です。
実は春休みにインターンで自然言語処理のプロジェクトをやって以来この領域が好きで、
今回はそのきっかけになった単語ベクトルの話をしていこうと思います(・x・)
※B3が趣味で書いているだけなので曖昧な説明、「数学的にアレ」な部分が散見されると思うのですが見つけた場合は優しくコメントいただけるととっても嬉しいです...
ちなみにつらつら書くだけより実際に実装してみたほうが頭に入りそうだな〜ということで3つの記事に分けて
基本のモデルを追うところからPythonで実際に実装するところまでやるつもりです!
最初2回は情報系を勉強する女子大生 Advent Calendar 2017 - Qiitaに、最後1回は自分の所属する東大電気電子電子情報工学科のアドベントカレンダー、
eeic (東京大学工学部電気電子・電子情報工学科) Advent Calendar 2017 - Qiitaに載せるつもりなので、興味があればそちらもみてみてください〜
今回の記事を書くにあたってスタンフォード大学のCS224N:Deep Learning for NLPの授業を参考にしています。
授業スライド、参考資料、課題、講義ビデオ全てネット上で公開されているので、自然言語処理における深層学習に興味がある方はぜひ見てみてくださいヾ(@°▽°@)ノ
単語の意味をどう表現するか
自然言語はそのままでは深層学習や機械学習モデルに入力として入れることはできず、なんらかの形でコンピュータが理解できる形で単語の意味を教えていかなくてはいけません。
一番シンプルなのは単語ごとになんらかのカテゴリだったり特性(good, negative, positive...etc)のラベルを振っていくとかができそうです。
WordNet | A Lexical Database for Englishは英単語がsynsetと呼ばれる同義語のグループに分類され、簡単な定義や、他の同義語のグループとの関係が記述されています。
NLTKという自然言語処理でよく使われるPythonのライブラリでこのWordNetのためのインテーフェイスがあり、以下の感じで「panda」のhypernym(上位語)が取得できます。
from nltk.corpus import wordnet as wn
panda = wn.synset('panda.n.01')
hyper = lambda s:s.hypernyms()
list(panda.closure(hyper))
ちなみに結果はこんな感じ。
[Synset('procyonid.n.01'), Synset('carnivore.n.01'), Synset('placental.n.01'), Synset('mammal.n.01'), Synset('vertebrate.n.01'), Synset('chordate.n.01'), Synset('animal.n.01'), Synset('organism.n.01'), Synset('living_thing.n.01'), Synset('whole.n.02'), Synset('object.n.01'), Synset('physical_entity.n.01'), Synset('entity.n.01')]
procyonid(アライグマ科), carnivore(肉食動物), placental(有胎盤類), mammal(哺乳類), vertebrate(脊椎動物), chordate(脊索動物), animal(動物),
organism(生体)m living_thing(生き物), whole(全体), object(物体)...
うん、上位語は正しそう!が、こんな感じのラベリングとか概念定義を存在する全単語にやるのはちょっと現実的に厳しそうです……
また同義語に対して細かい意味の違いを表現できないのではないかという指摘もされています。さすがにこれじゃ厳しい、ということで次に出てきたのがOne hotな単語表現でした。
One hotによる局所的な表現
例えばあるデータセットにN単語含まれるならばN次元のベクトルを作り、そのベクトルの中でt番目だけ1を立て、残りは全て零とするOne hot表現が用いられていました。
例えばもし異なる10単語が登場する文章が与えられた時、文章中に登場するhotelとmotelという単語はそれぞれ以下のように表現されることになります。
このような表現は何が問題なのでしょう?まずこの表現だと、もし単語数が数百万、数千万…と増えていくと、巨大で疎ベクトルが必要になり、計算コストもメモリも心配になります。
また、これ内積をちょっと計算してみると
直交しており、類似度が全くないとなってしまうことがわかります。motel, hotelという類似語についてのベクトル表現のはずなのに、類似度の概念をOne hotベクトルでは全く捉えることができないために失われてしまいます。これもあまり望ましくないですよね…
分散的な単語表現とは
単語の意味をより密なベクトル表現を使って単語を表現できないか、という考えがここから出てきます。例えば、1万の単語をそのままOne hotベクトルで表すと1万次元が必要になるけど、
これを100~300くらいの密なベクトルにできれば、コストを減らすこともできそうだし、単語間の類似性ももうちょっとちゃんと捉えられそうです。
こういった単語のベクトル表現を「分散的な単語表現」と呼びます。ここで大事になってくるのが、
distributional hypothesis(意味的に近い単語は同じ文章に出現するはずだ)というもので、Word2Vec, Glove, fastText等の著名なモデルではこの考えを元にしています。
分散的な単語表現の基本的な考え方
基本的にはあるwordとその周辺のcontext words(もし"I love dogs and cats"という文章があり、"dogs"というwordに着目するならcontextは"I", "love", "and", "cats"ということになります)の間の条件付き確率を求め、これをコーパス中の全ての単語に対して行い、全体での目的関数を最大化するようパラメータを調節します。
....よくわからないですね !!!! ということで分散的な単語表現を行うモデルのうち、おそらく一番有名なWord2Vecというモデルに焦点を当てて何を具体的に計算しているのか、考えてみます。
Word2Vecとは
Word2Vecモデルとは上で書いたような「単語を密なベクトルでいい感じに表現する」モデルの代表的なものの一つであり、米グーグル(当時)の研究者であるトマス・ミコロフ氏により提案されました。
「queen - woman = king」の例を耳にしたことのある方も多いのではないでしょうか。
密なベクトル表現により文章に含まれる単語同士の類似度や、単語間での加算・減算などができるようになり、
またニューラルネットワークの入力の素性に利用できるようになったことで、ディープラーニングの自然言語処理への応用が
進んだとも言われています。
Word2Vecのメインの二つのアルゴリズムに、前後の単語からある単語を予測する「CBoW」と、ある単語から周辺の単語を予測する「Skip-gram」があり、この二つがあるのですが、CBoWについて書いている最中にスタバwifiが切断された結果書きかけの記事が吹き飛んで萎えたので今回はとりあえずSkip-gramにフォーカスを当てたいと思います。
Skip-gram
Skip-gramはCBoWの逆の方向で考え、単語(word)からその周辺単語(context)を予測します。
例えば{"I", "love", "playing", "tennis", "pizza", "eating", "am"}のような単語が与えられた時、"I love playing tennis", "I love pizza"は文章として自然ですが、
"I am pizza"や"I tennis"はちょっと気持ち悪いですよね。
これが私たちが無意識に「"pizza"という単語が与えらられた時にはおそらく周りには"like", "eating"などの動詞がくるの」「"I"という主格代名詞の直後にいきなり"tennis"や"pizza"などの普通名詞が
登場するのはおかしい」と、ある単語からその単語が使われそうな文脈を予測しているためです。
Skip Gramではこんな感じで、ある単語が与えられた時、
その周辺(context)にはどんな単語がくるべきかを条件付き確率で表します。
例えばbankingという単語を中心に考えてみます。
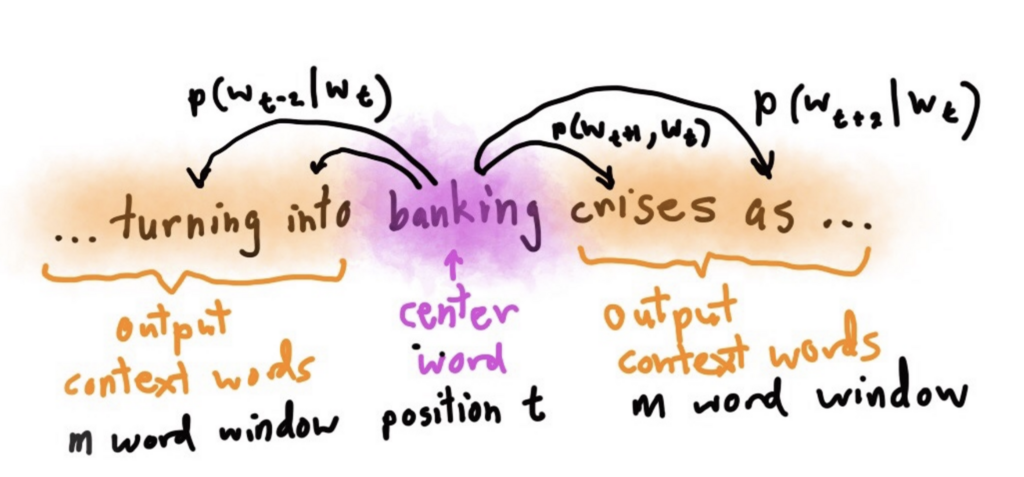
とすればある単語の前後100単語までは周辺単語と解釈することもできるのですが、実際私たちがある単語について考える時、ここまで離れた関係で考えたりはしないと思うので、windowサイズはそこまで大きく設定はされません。
上の例だとbankingとcrisisっていう単語は割と一緒に出てきそうなので、とかは確率として高くなるようになってほしいですね。
はおそらくありうるとは思うのですが、
よりは発生頻度が低くないなりそうなので、確率としてはやや低くなりそうです。
じゃあ実際にこの条件付き確率はどうやって計算し、また「こういう使い方はありえそう」というものをより高くするために、パラメータはどう調整するのでしょう。
Word2Vecでは次のようにソフトマックスでモデル化します。
は中心の単語
の周辺の単語を表ており、
は
の単語ベクトル、
は出力ベクトルを表ています。
はコーパス(学習に使う文章)に含まれる全ての単語を表ており、このように周辺単語
の出力ベクトル
と
の内積をとり、
それを正規化することで、
と
が共起する確率を求めます。
目的関数は、ある中心の単語を考えた時、実際にその周囲に出現した単語の条件付き確率の同時確率を最大化すれば良いので、以下のような目的関数を考えます。
このままだとちょっと計算しにくいので、対数尤度関数をとって、かつマイナスをかけて以下のような関数にします。
ここでは全ての最適化可能なパラメータを意味しています。
あとはパラメータをいい感じに最適化してこの関数を最小化するだけです! 実際にどう最適化するのかなどは次の記事で紹介しようと思います。今回はざっくりSkip-gramが何をしているのかが伝わればうれしいです :)
なんでこれ面白いと思ったの
※ここからは完全に個人的な私見です | _・)チラッ
自分の場合単語ベクトルの話が個人的に自然言語処理おもしろい!ってなった最初のきっかけの一つだったような気がします。
ある単語から周りにこんな単語がきそうだと予測する」(skip-gram)や「周辺の単語から中心の単語はこんな感じだろうと思う」(CBoW)の考え方って割と私たちが普段文章を読むときになんとなくやっている行動に近いなと思いました。
子供の頃小説を読んでいるときに特定の漢字が読めないときやTOEFLなどの英語の試験でわからない単語が出てきたとき、前後を読んで「多分この単語はこんな意味だろう」と予測を立てたり、文章を組み立てるときに「この単語と一緒に使われるべきはこれだな」って考えたりしませんか?
これを上のように数式できちんとモデル化して、しかも割と人間が見ても「あ、確かにその単語同士は似ているよね」「確かにその単語とその単語引くとそうなりそう!」みたいな関係性をきちんと捉えられるのってすごい面白いな〜(ふわ〜)と個人的には思っているので、今回記事を書いて見ました。
ざっくりと曖昧な説明でごめんなさいなのですが、少しでもへ〜って思っていただけたらうれしいです。